压缩
IO
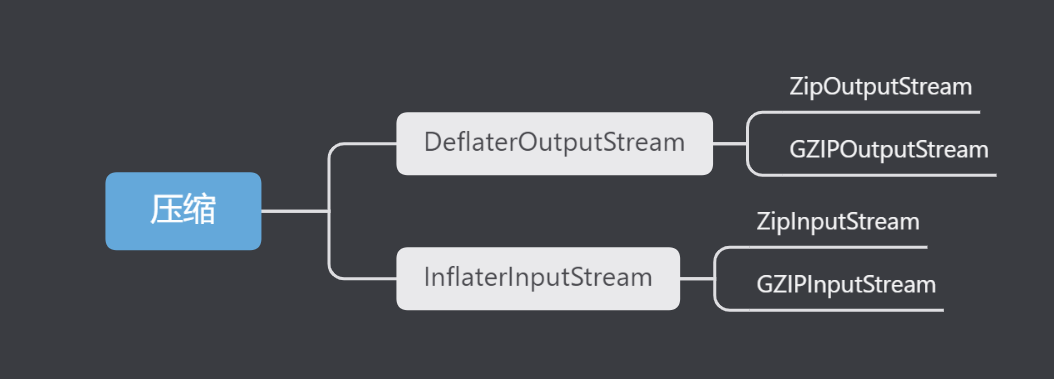
其中DeflaterOutputStream继承自FilterOutputStream,而InflaterInputStream继承自FilterInputStream,所以压缩相关的类操作的是字节流(这是显而易见的)。
用GZIP压缩单个文件
下面是一个将文件压缩和解压缩的简单示例:
package ch18.compress;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.zip.GZIPInputStream;
import java.util.zip.GZIPOutputStream;
public class Main {
public static void main(String[] args) throws IOException {
final String CURRENT_DIR = "./xyz/icexmoon/java_notes/ch18/compress/";
final String SOURCE_FILE = CURRENT_DIR + "Main.java";
final String COMPRESSED_FILE = CURRENT_DIR + "Main.gz";
final String UNCOMPRESSED_FILE = CURRENT_DIR + "Main.txt";
compress(SOURCE_FILE, COMPRESSED_FILE);
uncompress(COMPRESSED_FILE, UNCOMPRESSED_FILE);
}
/**
* 将指定文件压缩为目标文件
*
* @param sourceFile 源文件
* @param desFile 压缩后的文件
* @throws FileNotFoundException
*/
private static void compress(String sourceFile, String desFile) throws IOException {
BufferedInputStream bi = new BufferedInputStream(new FileInputStream(sourceFile));
GZIPOutputStream gos = new GZIPOutputStream(new FileOutputStream(desFile));
BufferedOutputStream bos = new BufferedOutputStream(gos);
try {
do {
int b = bi.read();
if (b == -1) {
break;
}
bos.write(b);
} while (true);
} finally {
bi.close();
bos.close();
}
}
/**
* 将指定文件解压缩为目标文件
*
* @param sourceFile 源文件
* @param desFile 解压后的文件
* @throws IOException
* @throws FileNotFoundException
*/
private static void uncompress(String sourceFile, String desFile) throws IOException {
BufferedInputStream bi = new BufferedInputStream(new GZIPInputStream(new FileInputStream(sourceFile)));
BufferedOutputStream bo = new BufferedOutputStream(new FileOutputStream(desFile));
try {
do {
int b = bi.read();
if (b == -1) {
break;
}
bo.write(b);
} while (true);
} finally {
bi.close();
bo.close();
}
}
}
运行这个示例就能看到目录下出现一个将Main.java压缩后的Main.gz文件,以及一个由Main.gz文件解压缩后的Main.txt文件。这其中Main.java和Main.txt文件的大小和内容完全一致,而Main.gz的大小是原始文件的1/3左右。
就像示例中的那样,使用GZIPInputStream和GZIPOutputStream压缩和解压文件相对简单,因为他们都是字节流的装饰器类,只要嵌套在输入流或输出流中就可以使用。
这里将
BufferedOutputStream嵌套在GZIPOutputStream外是有意义的,因为压缩的原理是尽可能合并多个相同的bit位来节省空间,这就意味着压缩算法需要读取尽可能多的内容来实现较高的压缩比,显然先缓冲再传递给GZIPOutputStream相比一个个传入byte更为有效。当然,这只是我个人的一个猜想,并没有研究和证明。
用ZIP压缩多个文件
除了压缩单个文件,更多的时候我们需要压缩多个文件到一个压缩文件:
package ch18.compress2;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.zip.Adler32;
import java.util.zip.CheckedInputStream;
import java.util.zip.CheckedOutputStream;
import java.util.zip.ZipEntry;
import java.util.zip.ZipInputStream;
import java.util.zip.ZipOutputStream;
public class Main {
public static void main(String[] args) throws IOException {
final String CURRENT_DIR = "./xyz/icexmoon/java_notes/ch18/compress2/test/";
String[] files = new String[] { "./LICENSE", "./README.md", "./.gitignore" };
String compressedFile = CURRENT_DIR + "files.zip";
compress(files, compressedFile);
uncompress(compressedFile, CURRENT_DIR);
}
private static void compress(String[] files, String compressedFile) throws IOException {
if (files.length == 0) {
return;
}
CheckedOutputStream cos = new CheckedOutputStream(new FileOutputStream(compressedFile), new Adler32());
ZipOutputStream zos = new ZipOutputStream(cos);
BufferedOutputStream bos = new BufferedOutputStream(zos);
zos.setComment("A compressed file.");
try {
for (String file : files) {
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(file));
try {
zos.putNextEntry(new ZipEntry(file));
do {
int b = bis.read();
if (b == -1) {
break;
}
bos.write(b);
} while (true);
bos.flush();
} finally {
bis.close();
}
}
System.out.println("checksum:" + cos.getChecksum().getValue());
} finally {
bos.close();
}
}
private static void uncompress(String compressedFile, String desDir) throws IOException {
CheckedInputStream cis = new CheckedInputStream(new FileInputStream(compressedFile), new Adler32());
ZipInputStream zis = new ZipInputStream(cis);
BufferedInputStream bis = new BufferedInputStream(zis);
try {
do {
ZipEntry entry = zis.getNextEntry();
if (entry == null) {
break;
}
String fileName = desDir + entry.getName();
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(fileName));
try {
do {
int b = bis.read();
if (b == -1) {
break;
}
bos.write(b);
} while (true);
} finally {
bos.close();
}
} while (true);
System.out.println("checksum:" + cis.getChecksum().getValue());
} finally {
bis.close();
}
}
}
这个示例展示了如何用ZipOutputStream压缩多个文件到一个文件,和之前不同的是,每次写入一个文件的数据前,需要先通过ZipOutputStream.putNextEntry写入一个文件标识,其它部分几乎没有什么区别。相应的,在解压时也需要先使用ZipInputStream.getNextEntry获取文件标识,然后再读取数据到文件中。
需要注意的是,在解压文件时,因为我们要批量写入所有源文件后再关闭输出流,并且每个被压缩的文件用ZipEntry进行区分,所以每写完一个源文件的数据后,都必须立即调用flush方法刷新数据到输出流,否则就会出现压缩后的文件被错误分割的情况(如果你尝试不刷新,就可以看到效果)。
示例中还使用了用于校验压缩和解压有没有出错的CheckedInputStream和CheckedOutputStream,这并非是必须的。
JAR包
Java程序通常都会被打成一个JAR包(Java ARchive,Java档案文件)使用,实际上JAR包也是一种压缩包,包含所有需要的Java代码和相关资源。使用JAR包可以更方便地传播和部署Java程序。
JDK包含一个命令行工具jar,可以创建和查看JAR包,但现代IDE基本都具备生成JAR包的能力,所以这里不做赘述,需要了解的可以自行查找相关内容。
序列化
序列化简单地说就是将对象转化为字节序列或者字符串,这是持久化技术的一种。相比数据库、XML、JSON等更常见的持久化技术,序列化的优点是可以简单直观地将对象持久化和恢复,缺点在于通常何种技术只能在同一编程语言内使用,也就是说用Java序列化后的对象只能用Java恢复,用PHP序列化的对象也只能由PHP来恢复。
相比与其它语言,Java实现序列化的方式相对简单。下面用一个简单示例来说明,在这个示例中,假设存在一个表示系统配置的Config对象,需要在程序加载时恢复,程序退出时保存,而这个持久化工作我们由对象序列化的方式实现。
package ch18.serilize2;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
class Config implements Serializable {
private String name;
private String password;
public Config() {
System.out.println("Config's constructor is called.");
}
public String getName() {
return name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public void setName(String name) {
this.name = name;
}
}
public class Main {
private static Config config;
private static final String CURRENT_DIR = "./xyz/icexmoon/java_notes/ch18/serilize2/";
private static final String SAVED_FILE = CURRENT_DIR + "config.out";
public static void main(String[] args) {
try {
loadConfig();
checkLogin();
saveConfig();
} catch (IOException | ClassNotFoundException e) {
throw new RuntimeException(e);
}
}
private static void checkLogin() throws IOException {
String name = config.getName();
if (name != null && name.length() != 0) {
System.out.println("Hello, " + name);
} else {
System.out.println("please login.");
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
System.out.print("enter your name:");
String nameInput = br.readLine();
System.out.print("enter your password:");
String pwdInput = br.readLine();
config.setName(nameInput);
config.setPassword(pwdInput);
}
}
private static void loadConfig() throws IOException, ClassNotFoundException {
File file = new File(SAVED_FILE);
if (file.exists() && file.isFile()) {
ObjectInputStream ois = new ObjectInputStream(new BufferedInputStream(new FileInputStream(file)));
try {
config = (Config) ois.readObject();
} finally {
ois.close();
}
} else {
config = new Config();
}
}
private static void saveConfig() throws IOException {
ObjectOutputStream oos = new ObjectOutputStream(new BufferedOutputStream(new FileOutputStream(SAVED_FILE)));
oos.writeObject(config);
oos.close();
}
}
第一次运行这个程序的时候会提示你输入用户名和密码,之后再运行就可以正常显示一段包含用户名的欢迎信息。
整个程序并没有使用数据库等常见的持久化技术,只使用了序列化并写入文件,就完成了类似的功能。
如果你需要让某个类实例能够序列化,就要像示例中的Config类那样,让其实现一个Serializable接口,该接口是一个标记接口,并不包含任何方法。之后你就可以使用ObjectOutputStream.writeObject方法将其写入一个输出流中保存。在这个示例中是写入到文件,当然也可以通过输出流写入到网络或者别的什么地方。
将序列化后的对象“恢复”也被称作“反序列化”,同样很简单,只要使用ObjectInputStream.readObject方法读取即可,不过该方法返回的是一个Object类型,需要我们向下转型为相应的实际类型。
总的来说Java的序列化和反序列化都相对简单,主要的工作都由Java虚拟机完成,开发者只要完成一小部分工作即可。不过有一个细节需要注意,序列化的过程中并不涉及构造函数的调用,而是虚拟机直接从序列化后的字节流中恢复数据来生成实例。此外,如果通过网络传递字节流并反序列化,必须有一个前提:本地的JVM要能够加载相应的类定义的class文件,否则就会产生ClassNotFoundException异常。
自定义序列化
大多数情况下,Java默认的序列化方式就够用了,但如果你需要对序列化有更详细的控制,可以使用Externalizable接口。
Externalizable接口继承自Serializable,它包含两个方法writeExternal和readExternal,分别对应序列化和反序列化。
我们用Externalizable改写之前的示例进行说明:
...
class Config implements Externalizable {
...
public void writeExternal(ObjectOutput out) throws IOException {
out.writeObject(this.name);
out.writeObject(this.password);
}
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
name = (String) in.readObject();
password = (String) in.readObject();
}
}
...
让Config实现Externalizable接口后,通过ObjectOutputStream.writeObject方法输出Config实例时,就会调用Config.writeExternal方法向输出流写入字节序列。在示例中就是简单地调用out.writeObject依次写入name属性和password属性(标准类库都实现了序列化相关接口)。相应的,在通过ObjectInputStream.readObject反序列化时,Config.readExternal方法就会被调用。
Externalizable与Serializable有一点有很大不同——在反序列化时,前者会调用默认构造函数,而后者不会。如果你重复执行上边的示例就会发现这一点。
这就意味着使用Externalizable接口存在一些限制,比如说如果该类有一个非public的默认构造函数,就会导致反序列化失败。
使用Externalizable接口的好处在于可以实现一些自定义的序列化和反序列化逻辑,比如我们可能不希望将用户密码已明码的方式序列化后保存,这样是危险的,通常的做法是只保存密码的MD5值:
...
class Config implements Externalizable {
...
public void writeExternal(ObjectOutput out) throws IOException {
out.writeObject(this.name);
String md5 = MyMD5Util.encrypt(password);
out.writeObject(md5);
}
...
}
...
MD5的具体生成方式是我参考自网上一篇文章的,具体可以查看本文的Github仓库或者末尾的参考资料列表。
这个示例只是用于说明
Externalizable的可能用途,实际上通常需要在获取到用户输入的密码后就立即对其MD5,然后所有的密码效验等都是比对MD5值是否相等,是不会将明码保存在Config实例的属性中的。目前这个示例是有缺陷的,第一次登陆时我们写入Config.password中的是明文密码,但之后反序列化后获取的是MD5后的值,这是有歧义的。但作为一个玩具示例,我不打算修正这个问题。
如果我们压根不需要保存用户的密码信息,可以更简单:
...
class Config implements Serializable {
private String name;
private transient String password;
public Config() {
System.out.println("Config's constructor is called.");
}
public String getName() {
return name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public void setName(String name) {
this.name = name;
}
}
...
需要注意的是,这里的Config实现的是Serializable接口,同时为password属性添加了一个transient关键字,其它具体的序列化细节依然是交给JVM来实现,如果运行这个版本的示例你就会发现,反序列化后的Config属性中包含name属性,但是password属性是null,换句话说,序列化时并没有保存password属性。
这就是transient关键字的用途:可以让Serializable对象的相应属性排除出“自动”序列化和反序列中。
需要注意的是,transient因为是作用于JVM执行的“自动序列化”过程中的,所以只能和Serializable接口搭配使用,而不能用于Externalizable接口。
如果你需要在使用Serializable接口时实现类似Externalizable那样的“自定义序列化逻辑”,同样是可以实现的:
...
class Config implements Serializable {
...
private void writeObject(java.io.ObjectOutputStream out) throws IOException {
out.writeObject(name);
out.writeObject(password);
}
private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException {
name = (String) in.readObject();
password = (String) in.readObject();
}
}
...
就像示例展示的,只要实现writeObject方法和readObject方法即可。JVM在具体执行序列化和反序列化操作时会“检查”Config实例,如果其具备这两个方法,就会调用以实现序列化和反序列化,而不会执行默认的逻辑。
有意思的是这两个方法是private的,且并不属于任何接口,但却被JVM执行序列化的相关组件可以探查和调用。这种方式在Java中是很不常见的,更类似于Python中的协议。实际上是通过反射机制来实现的。
最后要说明的是,如果需要在writeObject和readObject方法中执行默认的序列化和反序列化逻辑,可以这样做:
...
class Config implements Serializable {
...
private void writeObject(java.io.ObjectOutputStream out) throws IOException {
out.defaultWriteObject();
}
private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
}
}
...
写法很简单,只要调用ObjectOutputStream.defaultWriteObject和ObjectInputStream.defaultReadObject即可。比较奇怪的是这两个方法并不需要传入当前对象,也不会返回一个Config实例。这是因为在序列化和反序列化的过程中,输入流和输出流是持有当前对象的引用的。
此外,因为是执行的默认序列化和反序列化逻辑,所以此时transient关键字是生效的,你会看到被标记为transient的password属性没有被序列化。
持久化
如果只是将序列化用于简单地保存和恢复某个对象,可能没有什么问题,但如果是系统性地用序列化对某些数据进行持久化,就会有一些额外问题。
比如说有多个对象持有同一个对象的引用,那么序列化和反序列化后,得到的结果依然是指向同一个对象还是分别指向一个对象?
package ch18.serilize6;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
import java.util.LinkedList;
import java.util.List;
class Student implements Serializable {
private ClassRoom classRoom;
private String name;
public Student(String name) {
this.name = name;
}
public void setClassRoom(ClassRoom classRoom) {
this.classRoom = classRoom;
}
@Override
public String toString() {
return super.toString() + "-" + classRoom.toString();
}
}
class ClassRoom implements Serializable {
public void addStudent(Student student) {
student.setClassRoom(this);
}
}
public class Main {
public static void main(String[] args) throws IOException, ClassNotFoundException {
ClassRoom cr = new ClassRoom();
Student s1 = new Student("Li Lei");
Student s2 = new Student("Han Meimei");
Student s3 = new Student("Brus Lee");
cr.addStudent(s1);
cr.addStudent(s2);
cr.addStudent(s3);
List<Student> students = new LinkedList<>();
students.add(s1);
students.add(s2);
students.add(s3);
System.out.println(students);
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(s1);
oos.writeObject(s2);
oos.writeObject(s3);
oos.writeObject(students);
oos.flush();
ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(bos.toByteArray()));
Student s4 = (Student) ois.readObject();
Student s5 = (Student) ois.readObject();
Student s6 = (Student) ois.readObject();
List<Student> students2 = (List<Student>) ois.readObject();
System.out.println(s4);
System.out.println(s5);
System.out.println(s6);
System.out.println(students2);
}
}
// [ch18.serilize6.Student@372f7a8d-ch18.serilize6.ClassRoom@2f92e0f4,
// ch18.serilize6.Student@28a418fc-ch18.serilize6.ClassRoom@2f92e0f4,
// ch18.serilize6.Student@5305068a-ch18.serilize6.ClassRoom@2f92e0f4]
// ch18.serilize6.Student@5cb0d902-ch18.serilize6.ClassRoom@46fbb2c1
// ch18.serilize6.Student@1698c449-ch18.serilize6.ClassRoom@46fbb2c1
// ch18.serilize6.Student@5ef04b5-ch18.serilize6.ClassRoom@46fbb2c1
// [ch18.serilize6.Student@5cb0d902-ch18.serilize6.ClassRoom@46fbb2c1,
// ch18.serilize6.Student@1698c449-ch18.serilize6.ClassRoom@46fbb2c1,
// ch18.serilize6.Student@5ef04b5-ch18.serilize6.ClassRoom@46fbb2c1]
在这个示例中,有三个Student对象,他们都持有同一个ClassRoom对象的引用,而经过序列化和反序列化后,依然会保留这种关系,无论是按照单个Student对象操作,还是将它们添加进List中统一操作,都是相通的结果。
当然,前提条件是使用的是同一个输出/输入流,否则会建立两套“类关系网”:
package ch18.serilize7;
...
public class Main {
public static void main(String[] args) throws IOException, ClassNotFoundException {
ClassRoom cr = new ClassRoom();
Student s1 = new Student("Li Lei");
Student s2 = new Student("Han Meimei");
Student s3 = new Student("Brus Lee");
cr.addStudent(s1);
cr.addStudent(s2);
cr.addStudent(s3);
List<Student> students = new LinkedList<>();
students.add(s1);
students.add(s2);
students.add(s3);
System.out.println(students);
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
ByteArrayOutputStream bos2 = new ByteArrayOutputStream();
ObjectOutputStream oos2 = new ObjectOutputStream(bos2);
oos.writeObject(s1);
oos.writeObject(s2);
oos.writeObject(s3);
oos2.writeObject(students);
oos.flush();
oos2.flush();
ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(bos.toByteArray()));
ObjectInputStream ois2 = new ObjectInputStream(new ByteArrayInputStream(bos2.toByteArray()));
Student s4 = (Student) ois.readObject();
Student s5 = (Student) ois.readObject();
Student s6 = (Student) ois.readObject();
List<Student> students2 = (List<Student>) ois2.readObject();
System.out.println(s4);
System.out.println(s5);
System.out.println(s6);
System.out.println(students2);
}
}
// [ch18.serilize7.Student@372f7a8d-ch18.serilize7.ClassRoom@2f92e0f4,
// ch18.serilize7.Student@28a418fc-ch18.serilize7.ClassRoom@2f92e0f4,
// ch18.serilize7.Student@5305068a-ch18.serilize7.ClassRoom@2f92e0f4]
// ch18.serilize7.Student@5cb0d902-ch18.serilize7.ClassRoom@46fbb2c1
// ch18.serilize7.Student@1698c449-ch18.serilize7.ClassRoom@46fbb2c1
// ch18.serilize7.Student@5ef04b5-ch18.serilize7.ClassRoom@46fbb2c1
// [ch18.serilize7.Student@5f4da5c3-ch18.serilize7.ClassRoom@443b7951,
// ch18.serilize7.Student@14514713-ch18.serilize7.ClassRoom@443b7951,
// ch18.serilize7.Student@69663380-ch18.serilize7.ClassRoom@443b7951]
这个示例中使用了两套输入和输出流,分别用于序列化三个独立的Student对象和统一保存在List中的Student对象。结果是虽然反序列化后的两套Student对象依然保留着指向同一个ClassRoom对象这种特点,但两套Student对象之间不再有联系,他们的地址是不同的,也就是说反序列化后产生了6个Student对象和2个ClassRoom对象。
虽然目前来看序列化表现的都很好,但实际上它还有个缺陷——“无法保存static属性”。
package ch18.static1;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
import util.Fmt;
class Student implements Serializable {
public static int counter = 0;
private final int id = ++counter;
private String name;
public Student(String name) {
this.name = name;
}
@Override
public String toString() {
return Fmt.sprintf("Student(%d.%s)", id, name);
}
}
public class Main {
private static String CURRENT_DIR = "./xyz/icexmoon/java_notes/ch18/static1/";
private static String FILE = CURRENT_DIR + "data.out";
public static void main(String[] args) throws IOException, ClassNotFoundException {
File file = new File(FILE);
if (file.exists()) {
read();
file.delete();
} else {
write();
}
}
private static void write() throws IOException {
Student s1 = new Student("Han Meimei");
Student s2 = new Student("Li Lei");
Student s3 = new Student("Brus Lee");
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(FILE));
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(s1);
oos.writeObject(s2);
oos.writeObject(s3);
oos.close();
}
private static void read() throws IOException, ClassNotFoundException {
ObjectInputStream ois = new ObjectInputStream(new BufferedInputStream(new FileInputStream(FILE)));
Student s4 = (Student) ois.readObject();
Student s5 = (Student) ois.readObject();
Student s6 = (Student) ois.readObject();
System.out.println(s4);
System.out.println(s5);
System.out.println(s6);
System.out.println(Student.counter);
ois.close();
}
}
// Student(1.Han Meimei)
// Student(2.Li Lei)
// Student(3.Brus Lee)
// 0
在这个例子中,Student有一个静态属性counter,用于记录已创建的Student对象个数,并用于为Student对象初始化id属性。之后在第一次运行程序时,会创建三个Student对象,并在序列化后保存到文件。第二次运行会从文件反序列化,但如果此时打印Student.counter,就会发现其被初始化为0,而非我们期待的3。
这是因为序列化和反序列化只涉及对象的属性,而类属性是保存在类的Class对象中的,而Class对象并不会被同时序列化和反序列化。
当然
Class类本身也支持序列化,但问题在于将它们序列化保存是容易的,但利用它们恢复静态属性比较麻烦,可能需要手动编写一些反射代码,那样反而会让问题复杂化。
如果需要对static属性序列化和反序列化,就需要我们做出额外努力,比如:
package ch18.static2;
...
class Student implements Serializable {
...
public static void serializeStaticMember(ObjectOutputStream oos) throws IOException {
oos.writeInt(counter);
}
public static void unserializeStaticMember(ObjectInputStream ois) throws IOException {
counter = ois.readInt();
}
}
public class Main {
...
private static void write() throws IOException {
Student s1 = new Student("Han Meimei");
Student s2 = new Student("Li Lei");
Student s3 = new Student("Brus Lee");
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(FILE));
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(s1);
oos.writeObject(s2);
oos.writeObject(s3);
Student.serializeStaticMember(oos);
oos.close();
}
private static void read() throws IOException, ClassNotFoundException {
ObjectInputStream ois = new ObjectInputStream(new BufferedInputStream(new FileInputStream(FILE)));
Student s4 = (Student) ois.readObject();
Student s5 = (Student) ois.readObject();
Student s6 = (Student) ois.readObject();
Student.unserializeStaticMember(ois);
System.out.println(s4);
System.out.println(s5);
System.out.println(s6);
System.out.println(Student.counter);
ois.close();
}
}
// Student(1.Han Meimei)
// Student(2.Li Lei)
// Student(3.Brus Lee)
// 3
这里使用了一种最简单的方式,在Student中添加了两个类方法serializeStaticMember和unserializeStaticMember,它们分别负责将静态成员写入输出流或者从输入流中恢复,然后只要在合适的地方调用它们即可。
当然也可以使用我们之前介绍的方法来持久化静态属性:
package ch18.static3;
...
class Student implements Serializable {
...
private void writeObject(ObjectOutputStream out)
throws IOException {
out.defaultWriteObject();
out.writeInt(counter);
}
private void readObject(ObjectInputStream in)
throws IOException, ClassNotFoundException {
in.defaultReadObject();
counter = in.readInt();
}
}
...
// Student(1.Han Meimei)
// Student(2.Li Lei)
// Student(3.Brus Lee)
// 3
这样做甚至不需要修改其它部分的代码,但问题的关键在于实际上我们只需要在最后一个Student对象序列化后序列化Student的静态属性,并且在最后一个Student对象反序列化后反序列化Student的静态属性,也就是说只需要进行2次Student静态属性的序列化和反序列化工作,但示例中这种将其绑定到对象序列化工作中的做法,就会导致额外不必要的序列化和反序列化工作,这是一种额外开销。当然,实际上类似的取舍在计算机领域很常见,如果你觉得这些性能开销是可接受的,就可以采用这种方式。
Preferences
接触过Android开发的应该对Preferences不陌生,这是一种系统管理的,轻量级的持久化工具。可以帮助你将用户偏好等一些轻量级数据进行持久化。
有意思的是,Java也支持Preferences,且用途类似。
下面这个例子是用Preference改写之前用序列化实现的那个登录程序:
package ch18.references;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.prefs.Preferences;
class Config {
private String name;
private transient String password;
public Config() {
System.out.println("Config's constructor is called.");
}
public String getName() {
return name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public void setName(String name) {
this.name = name;
}
}
public class Main {
private static Config config;
private static Preferences preferences = Preferences.userNodeForPackage(Main.class);
public static void main(String[] args) {
loadConfig();
try {
checkLogin();
} catch (IOException e) {
throw new RuntimeException(e);
}
saveConfig();
}
private static void checkLogin() throws IOException {
String name = config.getName();
if (name != null && name.length() != 0) {
System.out.println("Hello, " + name);
System.out.println("password:" + config.getPassword());
} else {
System.out.println("please login.");
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
System.out.print("enter your name:");
String nameInput = br.readLine();
System.out.print("enter your password:");
String pwdInput = br.readLine();
config.setName(nameInput);
config.setPassword(pwdInput);
}
}
private static void loadConfig() {
String name = preferences.get("config.name", null);
if (name != null && name.length() != 0) {
config = new Config();
config.setName(name);
config.setPassword(preferences.get("config.pwd", ""));
} else {
config = new Config();
}
}
private static void saveConfig() {
preferences.put("config.name", config.getName());
preferences.put("config.pwd", config.getPassword());
}
}
可以通过Preferences.userNodeForPackage方法来获取一个Preferences,除此之外还有Preferences.systemNodeForPackage,它们没有本质上的区别,不过习惯上会使用前者保存用户个人数据,用后者保存程序的通用数据。
Preferences中的数据采用键值对形式保存,可以使用put方法保存数据,使用get方法获取数据。除了像示例中那样保存和获取字符串以外,还支持其它基础类型的数据,比如putInt和getInt等。但不能直接用于保存其它对象,并且对于字符串大小也有限制(不超过8K)。
需要注意的是,使用get时需要用第二个参数指定一个“缺省值”,也就是没有键值对时会返回的值,类似的操作其实在Map中也存在。
有意思的是改用Preferences后,你会发现不会生成数据文件,可能你会疑惑数据保存到哪里去了。实际上具体的实现方式与操作系统相关,如果是Windows,Preferences会使用注册表保存数据(注册表中的数据本身也是以键值对形式存在)。
因为本篇内容是上篇的补充,所以较短,除了这些内容以外,《Java编程思想》还介绍了使用XML进行持久化的内容,但我觉得书中使用的第三方类库已经很古老,并且JSON已经变得比XML更流行,且这部分内容更适合在用到时查询,不是太需要在持久化部分过多涉猎。
总之,就到这里了,谢谢阅读。


文章评论