这里的函数式编程,并非指面向过程编程。而更多的是一种将函数作为一等对象的编程语言中,函数在编程中灵活性体现的一种描述。
一等对象
关于什么是一等对象,《Fluent Python》一书给出的解释是——如果一个对象是一等对象,将具有以下特性:
-
运行时创建
-
能赋值给变量或容器中的元素
-
-
能作为函数的返回值结果
在我的印象中,Javascrip和Python中的函数都具有此类特性,具有相当高的灵活性。而其它语言都缺少这样或那样的特性。
函数对象
正如在中阐述过的那样,Python是门基于对象的语言,而函数也是对象。
def hello():
'''你好'''
print("Hello world!")
print(hello)
print(type(hello))
print(hello.__doc__)
# <function hello at 0x000001D402AF39D0>
# <class 'function'>
# 你好
通过type我们可以清楚地看到自定义函数hello是function类的一个实例,而且可以访问其属性,比如__doc__。
此外,函数对象还可以作为参数和返回值,这在构建函数修饰符的时候有明确体现,需要回顾和了解的可以阅读,此处不做过多赘述。
高阶函数
我们已经说明了函数本身是可以作为参数进行传递的,而通过参数接收函数的函数被称作高阶函数。
我知道这么说很绕,但意思不难理解。
在Python的常用函数中有这么几个高阶函数:
sorted
sorted常用于序列排序,之前在中我们介绍过。
我们知道,sorted可以指定一个参数key,改变默认的排序原则。
l = ["aa", "b", "ccc"]
print(sorted(l, key=len))
# ['b', 'aa', 'ccc']
就像上面展示的那样,key通过接收单参数函数对象的方式改变了sorted的默认排序原则。
所以说sort是一个高阶函数。
map
map函数的作用如同其名称揭示的那样,可以将一个函数应用于一个可迭代对象。
persons = [('Jack chen', 16, 'actor'),
('Brus lee', 20, 'engineer')]
def formatPerson(person: tuple):
return "name:%s,age:%s,actor:%s" % (person[0], str(person[1]), person[2])
formatPersons = list(map(formatPerson, persons))
print(formatPersons)
# ['name:Jack chen,age:16,actor:actor', 'name:Brus lee,age:20,actor:engineer']
map的返回值同样是一个可迭代对象,所以我们可以用list()承接并进一步处理。
这个例子中的formatPerson函数比较简单,所以我们也可以用匿名函数来改写:
persons = [('Jack chen', 16, 'actor'),
('Brus lee', 20, 'engineer')]
formatPersons = list(map(lambda person: "name:%s,age:%s,actor:%s" % (
person[0], str(person[1]), person[2]), persons))
print(formatPersons)
# ['name:Jack chen,age:16,actor:actor', 'name:Brus lee,age:20,actor:engineer']
但这样的代码可读性不高,幸运的是Python3提供了两个新的特性:推导式和生成器。我们完全可以用推导式完成类似的工作,还更具有可读性。
persons = [('Jack chen', 16, 'actor'),
('Brus lee', 20, 'engineer')]
formatPersons = ["name:%s,age:%s,actor%s" % (name,age,career) for name,age,career in persons]
print(formatPersons)
# ['name:Jack chen,age:16,actor:actor', 'name:Brus lee,age:20,actor:engineer']
所以,因为推导式和生成器的存在,map在Python3中的使用频率不高。
reduce
reduce函数接受一个两参数函数,会用这个函数来处理一个可迭代对象。
和map不同的是,reduce函数的处理逻辑是“累积式处理”。即每处理完一个可迭代对象的元素,会把其结果作为下一次处理中的一个参数。
这种处理方式的最常见概念是数学中的。
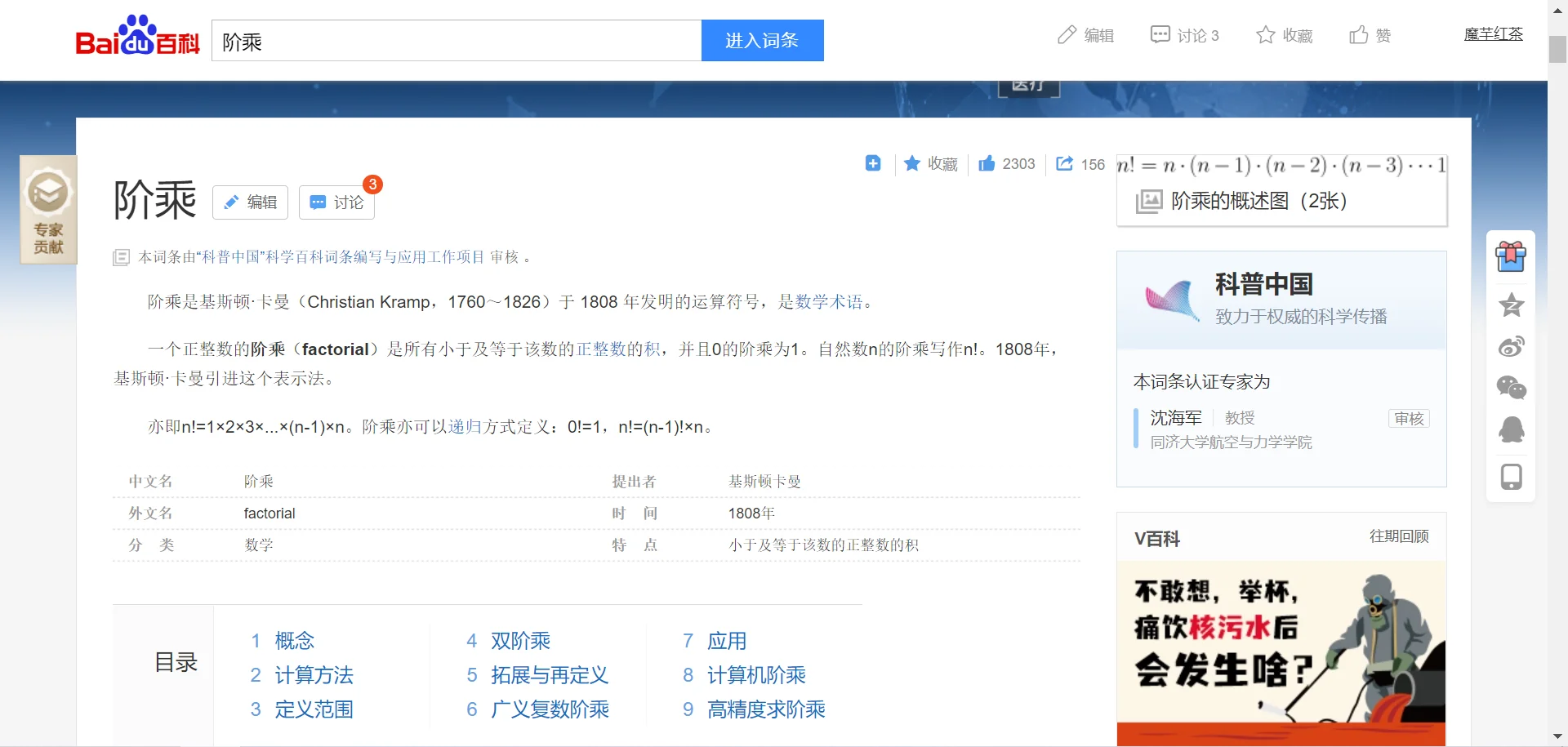
我们使用reduce来完成一个阶乘函数:
from functools import reduce
def factorial(n):
return reduce(lambda a, b: a*b, range(1, n+1))
print(factorial(1))
print(factorial(3))
print(factorial(5))
# 1
# 6
# 120
匿名函数
正如前面展示的那样,在某些使用高阶函数的场景,我们可能需要使用匿名函数,这样会避免不得不创建一些并不会频繁使用的“临时函数”。
匿名函数的语法是lambda args:expression。
其中args是匿名函数接收的参数列表,expression是作为匿名函数返回值的表达式。
和Java或别的主流语言相比,Python因为其奇特的语法特性(无{}函数体),匿名函数的使用相当受限。
其匿名函数的函数体只能包含简单的表达式,并不能编写复杂的多行代码。
可调用对象
概览
可调用对象即可以用obj()方式执行的对象。
Python手册对其有总结:
-
自定义函数
-
内置函数
-
内置方法
-
自定义方法
-
类
-
类实例
-
生成器函数
其中比较特殊的是类实例和生成器函数,生成器在之前的文章中已经介绍过了,类实例作为可调用对象的例子稍后将会介绍。
callable
在Python中,要判断一个对象是否为可调用对象,可以通过callable函数来判断。
def hello():
print("Hello world!")
class Test():
pass
test = Test()
print(callable(hello))
print(callable(Test))
print(callable(test))
print(callable(len))
# True
# True
# False
# True
print(callable(test))之所以是False,是因为它没有实现__call__,稍后我们可以看到可调用实例的例子。
可调用类实例
Python可以通过实现魔术方法__call__将一个类的实例变为可调用实例。
这或许在从其它语言的转行过来的程序员感到困惑。
class Person():
def __init__(self, name, age):
self.name = name
self.age = age
def __call__(self):
print("Name:%s Age:%s" % (self.name, self.age))
JackChen = Person('Jack Chen', 16)
BrusLee = Person('Brus Lee', 20)
JackChen()
BrusLee()
# Name:Jack Chen Age:16
# Name:Brus Lee Age:20
因为目前的Python实际开发经验并不丰富,所以我也很难判断这个特性的必要性,可能其在构建IDE或者一些特殊底层工具的时候具有优越性。
函数属性
函数作为function类的对象,自然有很多属性,我们可以通过dir函数查看:
def hello():
print('Hello world!')
print(dir(hello))
# ['__annotations__', '__call__', '__class__', '__closure__', '__code__', '__defaults__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__get__', '__getattribute__', '__globals__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__kwdefaults__', '__le__', '__lt__', '__module__', '__name__', '__ne__', '__new__', '__qualname__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__']
dir()会返回一个包含所有属性的列表。
有趣的是,我们可以使用集合运算来进一步筛选出函数独有,类没有的属性:
def hello():
print('Hello world!')
class Test():
pass
print(set(dir(hello))-set(dir(Test)))
# {'__annotations__', '__kwdefaults__', '__qualname__', '__call__', '__globals__', '__code__', '__name__', '__get__', '__defaults__', '__closure__'}
参数
Python中函数签名的参数定义相当灵活,这点我们在中已经见识过了。
但除了变长定位参数和变长关键字参数,还存在一个仅限关键字参数。
这里的”定位参数“,指的是那些通过参数位置传递的参数。
”变长定位参数“指的是参数签名中类似
*args的存在。”变长关键字参数“指的是参数签名中类似
**kwArgs的存在。
仅限关键字参数
这是一个相当让人费解的名词,但我也想不到合适的称呼,或许关键字限定参数也合适,但并不能更有助于理解。
直白地说,仅限关键字参数就是指那些不能通过定位参数传递,只能通过显式地关键字方式传递的参数。
我们用一个示例来说明:
def readFile(fileName, *, encoding='UTF-8'):
content = ''
with open(file=fileName, encoding=encoding, mode='r') as fopen:
content = fopen.read()
return content
print(readFile('test.txt'))
print(readFile('test.txt',encoding='UTF-8'))
print(readFile('test.txt','UTF-8'))
# 你好世界!
# 你好世界!
# Traceback (most recent call last):
# File "d:\workspace\python\test\test.py", line 9, in <module>
# print(readFile('test.txt','UTF-8'))
# TypeError: readFile() takes 1 positional argument but 2 were given
可以看到,示例中的参数encoding只能通过显式指明关键字或者默认缺省的方式传递,并不能通过定位参数的方式传递。这就是所谓的仅限关键字参数。
fileName, *, encoding='UTF-8'这样的函数签名或许让人感觉困惑,其实*是一个省略变量名的变长定位参数。因为仅限关键字参数的声明必须位于变长定位参数之后,所以如果你需要声明一个仅限关键字参数,但同时不需要用到变长定位参数,就可以这样写。这其实和拆包时候的_有异曲同工之妙。
需要强调的是,除了必须声明在变长定位参数之后,仅限关键字参数没有其它限制,同样可以定义默认值。
获取参数信息
编程语言往往会提供一些平时的应用开发不会用到的底层技术,比如Java中的类映射。
此类机制都是为了IDE或其它底层工具的开发提供语言层面的支持。
在Python中,我们同样可以通过一些途径来探测函数的参数构成信息。
函数属性
在之前的中我们筛选出了一些函数独有的属性。这其中有一些属性记录了函数的参数信息,可以让我们用来进行参数分析。
-
__defaults__,保存了普通参数的默认值。 -
__kwdefaults__,保存了仅限关键字参数的默认值。 -
__code__.co_varnames,保存了函数中的变量名。
def person(name, age=15, *args, career='actor', **kwArgs):
test = 'a function to test'
print(person.__defaults__)
print(person.__kwdefaults__)
print(person.__code__)
print(person.__code__.co_varnames)
# (15,)
# {'career': 'actor'}
# <code object person at 0x000002459B5BB5B0, file "d:\workspace\python\test\test.py", line 1>
# ('name', 'age', 'career', 'args', 'kwArgs', 'test')
可以看到,函数的代码信息都保存在__code__中,这是一个code对象,而参数名保存在__code__.co_varnames中,但是其中也包含函数体中的变量名。
这无疑很不方便,所幸Python提供两外一种方便的途径进行参数分析。
inspect
from inspect import signature
def person(name, age=15, *args, career='actor', **kwArgs):
test = 'a function to test'
personSig = signature(person)
print(personSig)
for name, param in personSig.parameters.items():
print(param.kind, ':', name, '=', param.default)
# (name, age=15, *args, career='actor', **kwArgs)
# POSITIONAL_OR_KEYWORD : name = <class 'inspect._empty'>
# POSITIONAL_OR_KEYWORD : age = 15
# VAR_POSITIONAL : args = <class 'inspect._empty'>
# KEYWORD_ONLY : career = actor
# VAR_KEYWORD : kwArgs = <class 'inspect._empty'>
可以看到,通过模块inspect可以很方便直观地分析给定函数的参数。
值得注意的是,通过param.kind,可以很容易分辨参数类型:
-
POSITIONAL_OR_KEYWORD:普通参数,也可以视作定位参数。
-
VAR_POSITIONAL:变长定位参数。
-
KEYWORD_ONLY:限定关键字参数。
-
VAR_KEYWORD:变长关键字参数。
除了用于分析函数参数构成,inspect还提供”绑定“参数列表,以检测传参是否正确,以及分析参数分配的功能。
from inspect import signature
def person(name, age=15, *args, career='actor', **kwArgs):
test = 'a function to test'
personSig = signature(person)
jackChen = {'name': 'Jack Chen', 'age': 16,
'career': 'actor', 'other': 'no message'}
bindArgs = personSig.bind(**jackChen)
for name, value in bindArgs.arguments.items():
print("%s=%s" % (name, value))
# name=Jack Chen
# age=16
# career=actor
# kwArgs={'other': 'no message'}
这对我们分析参数传递中遇到的问题很有用。
函数注解
所谓的函数注解就是指函数的参数注释。比如:
def person(name:str, age:int=15, *args:tuple, career:str='actor', **kwArgs:dict)->None:
test = 'a function to test'
需要说明的是,通过注解我们可以给参数添加上类型说明,但是Python的解释器并不会做类型检测,这只会对提高代码的可读性有所帮助。
相比别的主流语言,Python的函数注释功能相当”弱“。
强类型语言姑且不论,同样作为弱类型语言,PHP在这方面就好的多:
<?php
/**
* 创建person
*@param string $name 姓名
*@param int $age 年龄
*@param string $career 职业
*@return void
*/
function person($name, $age, $career)
{;
}
直观、高效、人性化。这种注释方式和Java一脉相承。
但再怎么说,我们也是一个卑微的学习者,而非编程社区的大佬,所以多说无益,学就是了。
Python的函数注解保存在属性__annotations__中:
from inspect import signature
def person(name:str, age:int=15, *args:tuple, career:str='actor', **kwArgs:dict)->None:
test = 'a function to test'
print(person.__annotations__)
# {'name': <class 'str'>, 'age': <class 'int'>, 'args': <class 'tuple'>, 'career': <class 'str'>, 'kwArgs': <class 'dict'>, 'return': None}
需要注意的是,如果参数有默认值,默认值要写在注解的后面,我经常犯错。。。
同样的,我们可以使用inspect模块对注释进行提取:
from inspect import signature
def person(name: str, age: int = 15, *args: tuple, career: str = 'actor', **kwArgs: dict) -> None:
test = 'a function to test'
personSig = signature(person)
for name, param in personSig.parameters.items():
print(param.annotation, name)
# <class 'str'> name
# <class 'int'> age
# <class 'tuple'> args
# <class 'str'> career
# <class 'dict'> kwArgs
支持函数式编程的包
operator
operator包提供一些基本的操作,很大程度上是为了避免频繁地构建匿名函数。
mul
我们在介绍高阶函数的时候创建过一个阶乘函数:
from functools import reduce
def factorial(n):
return reduce(lambda a, b: a*b, range(1, n+1))
print(factorial(1))
print(factorial(3))
print(factorial(5))
# 1
# 6
# 120
我们可以使用数学函数mul重写这段代码,避免使用匿名函数:
from functools import reduce
from operator import mul
def factorial(n):
return reduce(mul, range(1, n+1))
print(factorial(1))
print(factorial(3))
print(factorial(5))
# 1
# 6
# 120
其中mul与匿名函数完全等价。
itemgetter
itemgetter用于从一个可迭代对象获取元素。
from functools import reduce
from operator import itemgetter
persons = [('Jack chen', 16, 'actor'), ('Brus lee', 20, 'engineer')]
getName = itemgetter(0)
getCareer = itemgetter(2)
for person in persons:
print(getName(person),'->', getCareer(person))
# Jack chen -> actor
# Brus lee -> engineer
可以看到,itemgetter接收一个参数来说明获取的index并返回一个可调用对象,通过这个可调用对象,我们就能从可迭代对象上获取固定位置的元素。
当然,这个示例中看不出特殊性,因为使用拆包即可,这里提供一个更恰当的例子:
from functools import reduce
from operator import itemgetter
from pprint import pprint
persons = [('Jack chen', 16, 'engineer'), ('Brus lee', 20, 'actor')]
getCareer = itemgetter(2)
persons.sort(key=getCareer)
pprint(persons)
# [('Brus lee', 20, 'actor'), ('Jack chen', 16, 'engineer')]
这个例子是依据职业对persons列表进行排序。
其中persons.sort(key=getCareer)与persons.sort(key=lambda person:person[2])等效。
我们通过getCareer = itemgetter(2)构建了一个从可迭代对象中获取第三个元素的可调用对象,然后将这个对象传递给了sort的参数key。
attrgetter
attrgetter与itemgetter类似,不过不是通过下标,而是通过属性名来获取元素。
from collections import namedtuple
from operator import attrgetter
person = namedtuple('person', 'name age career')
jackChen = person('Jack Chen', 16, 'actor')
brusLee = person('Brus Lee', 20, 'engineer')
getName = attrgetter('name')
getCareer = attrgetter('career')
print(getName(jackChen), '->', getCareer(jackChen))
print(getName(brusLee), '->', getCareer(brusLee))
# Jack Chen -> actor
# Brus Lee -> engineer
特别的,attrgetter还支持嵌套调用,我们看一个更复杂的例子:
from collections import namedtuple
from operator import attrgetter
person = namedtuple('person', 'name age career favorites')
favorites = namedtuple('favorites', 'music dog cat')
jackChen = person('Jack Chen', 16, 'actor', favorites(False, True, True))
brusLee = person('Brus Lee', 20, 'engineer', favorites(False, False, True))
getName = attrgetter('name')
getCareer = attrgetter('career')
isLikeCat = attrgetter('favorites.cat')
isLikeDog = attrgetter('favorites.dog')
print(getName(jackChen), 'like' if isLikeDog(jackChen) else 'not like', 'dog')
print(getName(brusLee), 'like' if isLikeDog(brusLee) else 'not like', 'dog')
# Jack Chen like dog
# Brus Lee not like dog
可以看到,通过.操作符我们可以进行嵌套访问。
methodcaller
通过methodcaller我们可以调用实例的指定方法。
from operator import methodcaller
toUpper = methodcaller('upper')
s = 'abcdefg'
print(s.upper())
print(toUpper(s))
# ABCDEFG
# ABCDEFG
示例中s.upper()与toUpper(s)的效果完全一致。
当然这个示例并没有什么实际用途,仅用于演示。
functools
同样的,functools包也提供了一些很有用的高阶函数。
比如之前介绍过的,还有接下来要介绍的partial。
partial
partial提供一个很有意思的功能,它可以”固化“函数的某些参数。
假设我们有这么一个计算器函数:
def calculator(mode, x, y, opertor):
if mode == 'simple':
pass
elif mode == 'math':
pass
else:
pass
我们通过参数mode可以决定当前的计算器是简单模式还是科学计算之类的复杂模式。
如果我们需要把这个功能提供给一些只会用到简单运算,根本不会用到复杂模式的用户,我们可以通过partial来"固化"一个简单计算器:
from functools import partial
def calculator(mode, x, y, opertor):
if mode == 'simple':
print('this is a simple calculator')
pass
elif mode == 'math':
pass
else:
pass
simpleCal = partial(calculator, 'simple')
simpleCal(1, 2, 'add')
可以看到,用户通过simpleCal正常使用计算器功能,并且不会发现这是我们通过"固化"的方式快捷生成的简单版本。
好了,关于函数式编程的相关内容我们探讨完毕,我居然花了整整一个下午的时间写这篇博客,希望能有人喜欢。
谢谢阅读。
对了,忘了附上思维导图:



文章评论