字符与字节
字符与字节是个编程里绕不开的话题,这东西属于那种一般平时用不到,但又不能不讲,而且还不容易理解的内容。
不过用类似的问题也很容易区分科班和非科班程序员。
话扯远了,我们回到字符和字节。从宏观上来说,字节就是机器编码,是方便于计算机存储的,而字符恰恰相反,是便于人类读写的。
最早的编码是什么我不清楚,不过ASCII应该是早期实用最广泛的编码。我现在依然能依稀回想起大学《C++大学教程》里那页ASCII编码表。
我们都知道,一个字节(byte)对应计算机里8个bit位,能表示2^8=256种可能性,对应的整数范围是0~255。
而ASCII就是用0~255编码了256种字符。
当然,这么“精简”的字符集在现代人看来会显得很不可思议,要知道现在可是个连emoji笑脸都要各种肤色都有的时代(大雾)。
所以我们发明了各种各样的编码来适应越来越多的需求,而UTF无疑是目前的佼佼者。
下面我们讨论一下Python中编码相关的各种问题。
转换
Python中字符和字节的转换很方便:
hellowStr = "Hellow world!"
hellowByte = bytes(hellowStr, encoding='ascii')
print(hellowByte)
print(hellowByte[0])
# 输出
# b'Hellow world!'
# 72
我们可以看到,字符串转换成了一个b'Hellow world'形式的东西,这个写法正是字节序列的字面量,也就是说我们可以用这种写法直接构建字节序列。
字节序列同样可以进行切片操作,可以看到第一个元素输出是72。
可以通过查看ASCII编码表:
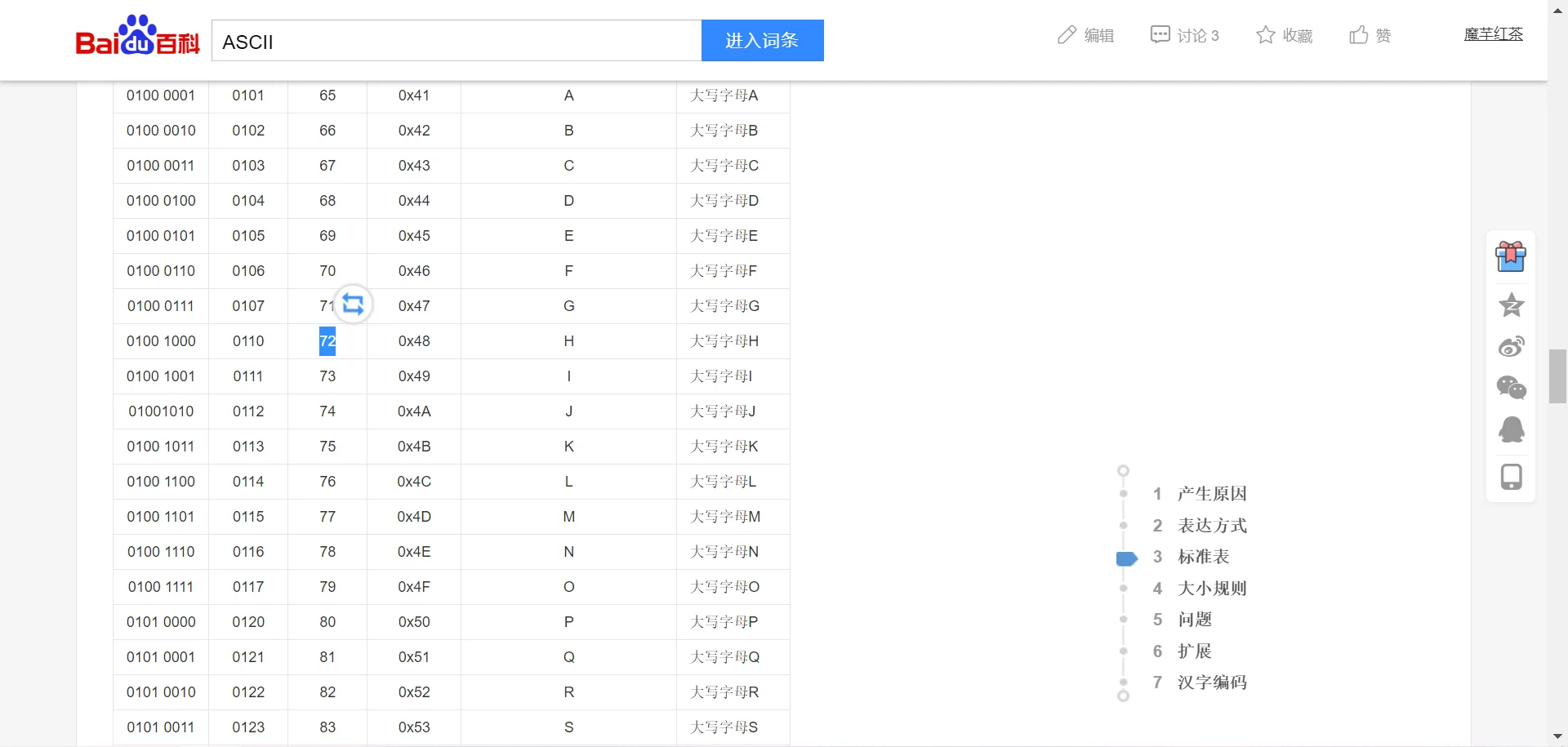
可以看到72对应的正是大写字母H。
虽然我们可以实用str()或bytes()进行转换,但更常用的字节编码/解码方式是实用encoding和decoding,我们看下面的例子:
hellowBytes = "Hellow wolrd!".encode(encoding='ascii')
print(hellowBytes)
print(hellowBytes[0])
hellowStr = hellowBytes.decode(encoding='ascii')
print(hellowStr)
# b'Hellow wolrd!'
# 72
# Hellow wolrd!
这种方式显式地表明了我们正在进行ASCII编码/解码工作。
老实说,我以前也经常对编码和解码傻傻分不清,很多时候只是手熟罢了。
要是细究的话,编码就是将字符串转化为目标编码,比如ASCII就是将字符对应到0~255这256个编码上。
这个概念不仅仅存在于字节编码,比如JSON,我们将程序中的原生容器序列化为JSON格式的文本,就是进行JSON编码,从JSON文本反序列化为原生容器就是在进行JSON解码。
对于字节编码,还有一种更便于理解的方式:编码就是将人类语言转换为机器码,解码就是将机器码转换成人类能理解的字符串。
字节数组
除了字节序列,Python还提供了字节数组作为字节操作的一种容器。
hellowBytes = "你好 世界!".encode(encoding='UTF-8')
print(hellowBytes)
print(hellowBytes[0:6])
subBytes = hellowBytes[0:6]
print(subBytes.decode(encoding='UTF-8'))
hellowByteArray = bytearray(hellowBytes)
print(hellowByteArray)
print(hellowByteArray[0:6])
print(hellowByteArray[0:6].decode(encoding='UTF-8'))
# b'\xe4\xbd\xa0\xe5\xa5\xbd \xe4\xb8\x96\xe7\x95\x8c\xef\xbc\x81'
# b'\xe4\xbd\xa0\xe5\xa5\xbd'
# 你好
# bytearray(b'\xe4\xbd\xa0\xe5\xa5\xbd \xe4\xb8\x96\xe7\x95\x8c\xef\xbc\x81')
# bytearray(b'\xe4\xbd\xa0\xe5\xa5\xbd')
# 你好
这里我们实用了中文和UTF-8编码,可以更好的观察字节码和字符的区别。
可以看到,经过UTF-8编码,字节序列编程了类似\x??这种形式,而一个\x??正是两位16进制数。
UTF-8是一种变长编码,这说明其编码后的字节长度不确定。具体实现中会把一个字符编码为1~4个字节,其中1个字节是8位,正好可以表示为2位16进制数(2组2^4),也就是说示例中的\xe4正好表示一个字节。事实上大多数语言编码使用3字节就够了,很少有语言会用到4字节。
我们观察可以观察到一个明显的空格,这是因为UTF-8是兼容ASCII的,而控制台可以正常地显示ASCII编码符号。空格前正好是6字节,对应你好。
UTF-8的百科词条见。
此外,示例程序还展示了字节数组,其使用方式和字节序列极为相似。
内存视图
Python提供一个特殊容器memoryview,我们可以称它为内存视图。
内存视图可以提供一种在不创建副本的情况下操作数据的能力,其实质是一种内存共享技术。
with open(file='test.png',mode='rb') as fopen:
imgView = memoryview(fopen.read())
headerView = imgView[0:10]
headerBytes = bytes(headerView)
print(headerBytes)
#b'\x89PNG\r\n\x1a\n\x00\x00'
这段代码展示了使用memoryview读取二进制图片文件的头信息。
需要特别说明的是headerView = imgView[0:10]这种切片操作并不存在数据复制行为,这和其它容器(列表/数组等)有着显著区别,所以视图更适合海量数据下的操作。
编码
因为历史原因,计算机世界的编码千千万万,非常复杂,作为一个天朝人,我们熟悉的编码应该是gb2312和UTF-8这两种。
说起来这似乎和“天下大势,分久必合合久必分”很相似,最早只有使用英语的人使用计算机,所以只有ASCII。其后各个国家的人加入,并且发展了各自的编码体系以兼容本国语言,比如gb2312。现在全球化,所以大一统趋势不可阻挡,就有了UTF家族。
从编码发展史我们就能知道,不同的编码自然有其限制,比如我们国人的早期编码gb2312,自然不能正常显示日语和韩语,反之亦然。而UTF-8可以显示所有的语言。但是并不是所有的地方都使用UTF编码,自然就会产生很多编码/解码问题。
编码问题
encodeError
"你好世界!".encode("ascii")
# Traceback (most recent call last):
# File "d:\workspace\python\test\test.py", line 1, in <module>
# "你好世界!".encode("ascii")
# UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-4: ordinal not in range(128)
编码问题很好理解,编码集不支持需要编码的字符串。
这就相当于我只有一本英汉字典,你却要求我查一下日语怎么说Hellow word。
解决方法也很简单,英汉字典搞不定的我可以问Google啊,UTF大概就是编码界的Google了。
除了这种简单粗暴的处理方案,Python还提供其它错误处理方案:
hellowBytes = "你好世界ABC!".encode("ascii",errors='ignore')
print(hellowBytes)
print(hellowBytes.decode('ascii'))
hellowBytes = "你好世界ABC!".encode("ascii",errors='replace')
print(hellowBytes)
print(hellowBytes.decode('ascii'))
# b'ABC'
# ABC
# b'????ABC?'
# ????ABC?
像示例演示的那样,我们可以在编码时指定错误处理方案。可以很容易搞明白ignore与replace的区别。
如果预设方案不能满足需要,我们还可以通过其它方式自建错误处理,在此不做过多讨论。
decodeError
解码错误和编码类似,都是一种牛头不对马嘴式的错误。
hellowBytes = "你好世界ABC!".encode("UTF-8",errors='ignore')
hellowStr = hellowBytes.decode(encoding='gb2312',errors='ignore')
print(hellowStr)
hellowStr = hellowBytes.decode(encoding='gb2312')
# 浣濂戒ABC锛
# Traceback (most recent call last):
# File "d:\workspace\python\test\test.py", line 4, in <module>
# hellowStr = hellowBytes.decode(encoding='gb2312')
可以看到,即使指定了错误处理方案,也会得到类似火星文的东西。
但是和编码错误不同的是,解码的时候可没有万能Google可以用,我们必须知道编码的时候使用的是何种字符集,才能正确解码。
此外,还有可能是编码字节本身损坏导致的解码错误,这不在讨论范围。
syntaxError
syntaxError是Python的历史遗留问题,在Python2的时代,Python编译器是使用ASCII编码,如果你用其它编码编写程序就会出现这个错误(当然注释中也不能存在其它编码)。
当然,Python2也不是完全不支持其它编码,只要在源代码的头部加上一行注释说明编码就行。
但是我们使用的是Python3不是吗,Who care?
如何找出编码
如同我们之前讨论的,解决解码错误的最大困难在于如何确定原始编码方案。虽然我们也不是很懂为什么把编解码搞得和谍战片的密码破译一般。
最最让我吃惊的是解决此问题的途径居然还真用到了密码学的内容。
如果你了解或者阅读过一点密码学科普小文的话,你可能对为什么理论上无解的密码会被敌人破解这事有一点了解。
而一段未知的字节编码就是那段理论上无解的密码。
而这其中的原理在于自然语言是有规律的,比如通过词频统计,我们可以知道哪些单词和标点出现的频率会远远高于其它单词和标点,进而我们可以对密码进行词频统计并对照比对。
我第一次阅读到这个的时候简直惊掉了下巴。
Python中恰好有个第三方包用这个原理实现了“字符集探测”。
这就是编码界的“终极机密”啊。
CharDet
这个堪称“终极机密”的包叫做CharDet,pypi页面是

官方页面居然显示支持多种中文编码,我本来不打算尝试的。。。
import chardet
hellowStr = "你好世界!"
hellowBytes = hellowStr.encode("UTF-8")
print(chardet.detect(hellowBytes))
hellowBytes = hellowStr.encode('gb2312')
print(chardet.detect(hellowBytes))
hellowStr = "当时时间仓促,就简单的配置了下,今天来探讨下如何使用Windows Teriminal进行SSH连接"
hellowBytes = hellowStr.encode('gb2312')
print(chardet.detect(hellowBytes))
# {'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
# {'encoding': None, 'confidence': 0.0, 'language': None}
# {'encoding': 'GB2312', 'confidence': 0.99, 'language': 'Chinese'}
可以看到,三次探测两次失败,可能是utf-8编码比gb2312更有特点,更容易识别。但我们可以注意到,原字符串越长,越容易被识别。这也很好理解,因为是用密码学原理“破译”嘛,样本更长当然更利于“破译”工作。
处理文本文件
一般来说,我们并不会经常处理文本和字节序列且需要在其中做转换,但我们依然需要为可能出现的类似工作做一些准备,理清处理思路和其中可能的坑。
整体思路
首先要明确,字节码是不会考虑人类的可读性的,其本来用途就是用于计算机存储,所以非必要不要直接操作字节码。
既然如此,我们处理文本的主要思路应该是采用以下步骤:
-
字节序列转换为字符串。
-
对字符串进行文本处理工作。
-
字符串转换为字节序列。
《Fluent Python》一书称之为汉堡包结构。
明确编码
虽然我们已经明确了整体处理思路,但是这其中还涉及一个坑,将字节序列转换为字符串的时候需要指明编码方式吗?可以依赖于编程环境的默认编码吗?
我们来看一个示例:
with open(file='test.txt', mode='w', encoding='UTF-8') as fopen:
print("你好世界!", file=fopen)
with open(file='test.txt', mode='r') as fopen:
print(fopen)
# <_io.TextIOWrapper name='test.txt' mode='r' encoding='cp936'>
可以看到使用open以文本方式读取文件的时候,Python会自动转换字节码为字符串,但是并不能智能地根据文件的实际编码方式进行正确解码,不仅如此,默认的解码方式还和具体操作系统有直接关系。
对于Unix/Linux系统,编码和解码默认都会使用UTF-8进行,而Windows使用的是cp936。
所以这段代码可能会在不同的操作系统上有不同的效果,对于这样的情况,我们必须要遵循明确编码的原则,即所有的文件读写都明确指明字符集,不使用平台相关的默认字符集。
规范化Unicode字符串
规范化
前边说过了,Unicode字符集很强大,相当于字符集世界的Google,但是同时它也很庞杂,为了一些兼容性或者别的天知道为什么的原因,在使用Unicode字符集的时候我们会遇到一些奇怪的现象:
from unicodedata import normalize
s1 = "café"
s2 = "cafe\u0301"
print(s1, s2)
print(s1 == s2)
print(len(s1), len(s2))
print(bytes(s1, encoding='UTF-8'), bytes(s2, encoding='UTF-8'))
# café café
# False
# 4 5
# b'caf\xc3\xa9' b'cafe\xcc\x81'
é是葡萄牙语中的一个重音字符,s1和s2打印到控制台的时候两者表现是完全一样的。但是,如果我们进行字符串比较,得出的结果却是False。同时,我们通过len来查看字符串长度,两者也并不相同,后者要多一个字符。
如果我们将两者都转换为Unicode字节序列,就能很明显看到两者差异,caf这三个字符编码一致,区别在于最后一个字符,前者是\xc3\xa9,用两个字节来编码é。后者是用e\xcc\x81,通过一个字节的普通方式编码的字符e,和\xcc\x81两字节编码的重音符号,用这种“组合字符”的方式来实现é这个重音字母。
我本来想举一个中文例子的,但没有检索到中文Unicode字符集中有类似的组合字符。
像这种组合字符的方式还有很多,这就给Unicode编码的字符串比较带来一些问题。
Unicode的解决方案是“规范化”。
具体规范化使用的是unicodedata模块的normalize方法。
具体的规范化包括四种实现:NFC/NFD/NFKC/NFKD。
其中NFC和NFD比较常用,NFC指的是最少码位构成的等价字符串。而NFD恰好相反,NFD会把组合字符拆解成基本字符和单独的“附加字符”。
通过规范化,我们就可以正确比较“等价”的Unicode字符串。
from unicodedata import normalize
s1 = "café"
s2 = "cafe\u0301"
print(normalize('NFC', s1) == normalize('NFC', s2))
print(normalize('NFD', s1) == normalize('NFD', s2))
# True
# True
NFKC和NFKD的规范化更为宽泛,会将“兼容性”的字符进行拆分,拆分为基础字符,转换过程中会出现信息损失的情况。
from unicodedata import normalize
s = "9¹²"
print(normalize('NFKC', s))
# 912
可以看到,9的12次方被规范化成了912,这有些让人难以接受。
但是这种转换在搜索的时候是很有用的,不是很准确的输入也可以匹配到想要的结果。但是要尽量避免将处理后的数据进行持久化,因为那样的数据往往是精度损失的,不准确的。
更多的转换示例这里就不展示了,我是数学字符打印苦手。
大小写转换
事实上,Unicode字符集是有个数据库的,每一个字符都有相应的记录,会记录其编码、名称等,并且会记录其大小写对应的字符。所以Unicode字符串可以依据这个数据库记录来实现大小写转换。
Python中的Unicode大小写转换通过casefold方法实现。
from unicodedata import name
s = "ABC".casefold()
print(s)
s = "ABC".lower()
print(s)
# abc
# abc
事实上在大多数情况下casefold与lower的表现一致,只是在一些特殊的Unicode字符的时候会有差异。同样的,我这个打字苦手就不展示了。
实用函数
经过前面的讨论,这里引出两个工具函数,通过规范化和大小写转换,提供对等价Unicode字符串的一致性比较。
from unicodedata import normalize
def nfcEqual(s1, s2):
return normalize('NFC', s1) == normalize('NFC', s2)
def foldEqual(s1, s2):
return normalize('NFC', s1).casefold() == normalize('NFC', s2).casefold()
Unicode文本排序
在学习编程语言和算法的时候,涉及到排序的,我们通常只针对ASCII字符进行排序,比较依据也很简单,只要比较编码大小即可。
相对的,Unicode字符集因为其复杂性,相应的排序也会相当复杂。
l = ["你好","我好","大家好"]
print(sorted(l))
#['你好', '大家好', '我好']
我们看到上面的排序方式并不符合中文习惯。
locale
Python提供使用操作系统本地化的功能进行Unicode字符排序,但这相当麻烦且坑颇多。
这种方式严重依赖于平台,且相同平台的不同版本都有可能会有不同的表现。
所以这里并不推荐,且不做演示。
PyUCA
对于Unicode字符串排序,Python有一个第三方包提供更好的支持:PyUCA。
其Pypi页面是。
页面介绍页居然是空白,嗯,蛮有个性的。
import pyuca
ct = pyuca.Collator()
l = ["你好", "我好", "大家好"]
print(sorted(l, key=ct.sort_key))
#['你好', '大家好', '我好']
嗯,比较尴尬,只能说对中文并没有很好的支持。
Unicode数据库
前边已经说过了,Unicode编码有一个数据库,来记录每个字符的信息,利用这些信息我们可以完成大小写转换等工作,同样的,也可以判断一个Unicode字符是否是一个数字,甚至对其进行数字化。
import re
import unicodedata
reDigit = re.compile(r'\d')
s = "1\xbc\xb2\u0969\u136b\u216b\u2466\u2480\u3285"
for char in s:
print("U+%04x" % ord(char),
char.center(6),
're_dig' if reDigit.match(char) else '-',
'is_dig' if char.isdigit() else '-',
'is_num' if char.isnumeric() else '-',
format(unicodedata.numeric(char), '5.2f'),
unicodedata.name(char),
sep='\t')
# U+0031 1 re_dig is_dig is_num 1.00 DIGIT ONE
# U+00bc ¼ - - is_num 0.25 VULGAR FRACTION ONE QUARTER
# U+00b2 ² - is_dig is_num 2.00 SUPERSCRIPT TWO
# U+0969 ३ re_dig is_dig is_num 3.00 DEVANAGARI DIGIT THREE
# U+136b ፫ - is_dig is_num 3.00 ETHIOPIC DIGIT THREE
# U+216b Ⅻ - - is_num 12.00 ROMAN NUMERAL TWELVE
# U+2466 ⑦ - is_dig is_num 7.00 CIRCLED DIGIT SEVEN
# U+2480 ⒀ - - is_num 13.00 PARENTHESIZED NUMBER THIRTEEN
# U+3285 ㊅ - - is_num 6.00 CIRCLED IDEOGRAPH SIX
我们可以看到正则表达式模块re对Unicode字符的识别并不完善,仅能处理阿拉伯数字或者梵文数字。Pypi中有个regex模块,其目的是取代re模块,提供对Unicode字符更好的支持。
支持字符串和字节序列的双模式API
这个小标题很唬人,但是要说明的内容很简单直白,就是介绍一些可以同时接受字符串和字节序列为参数,并能合理处理之的Python内建的API。
re
re作为内建的正则表达式模块,支持这种“双模式”。
import re
reNumStr = re.compile(r'\d+')
reWordStr = re.compile(r'\w+')
reNumBytes = re.compile(rb'\d+')
reWordBytes = re.compile(rb'\w+')
s = ("Ramanujan saw \u0be7\u0bed\u0be8\u0bef"
"¼ 1 2 3 Ⅻ")
b = s.encode(encoding='UTF-8')
print('numbers')
print(reNumStr.findall(s))
print(reNumBytes.findall(b))
print('words')
print(reWordStr.findall(s))
print(reWordBytes.findall(b))
# numbers
# ['௧௭௨௯', '1', '2', '3']
# [b'1', b'2', b'3']
# words
# ['Ramanujan', 'saw', '௧௭௨௯¼', '1', '2', '3', 'Ⅻ']
# [b'Ramanujan', b'saw', b'1', b'2', b'3']
这个例子能看出,re在字符和字节序列下都能正常工作,但在字节序列下,功能并不完备,对一些Unicode特殊字符无法识别。
os
os模块同样支持“双模式”,毕竟我们天朝人的文件路径很多都是中文,要是不能正确处理Unicode字符那直接就没法使用。
import os
import pprint
with open(file='测试.txt',mode='w',encoding='UTF-8') as fopen:
pass
pprint.pprint(os.listdir('.'))
pprint.pprint(os.listdir(b'.'))
# ['.vscode',
# 'array.file',
# 'carrier_game',
# 'carrier_game.zip',
# 'carrier_game_error',
# 'response.html',
# 'test.png',
# 'test.py',
# 'test.txt',
# '测试.txt']
# [b'.vscode',
# b'array.file',
# b'carrier_game',
# b'carrier_game.zip',
# b'carrier_game_error',
# b'response.html',
# b'test.png',
# b'test.py',
# b'test.txt',
# b'\xe6\xb5\x8b\xe8\xaf\x95.txt']
可以看到,如果你给listdir传入字节序列作为参数,它也能正常返回字节序列的目录列表。
如果我们遇到某些不能阅读和打印的文件名称,完全可以用它的字节序列名称与os模块正常交互。
好了,这部分内容真是个大工程,即使阅读《Fluent Python》的时候感觉很流畅,写起来各种艰涩难明。
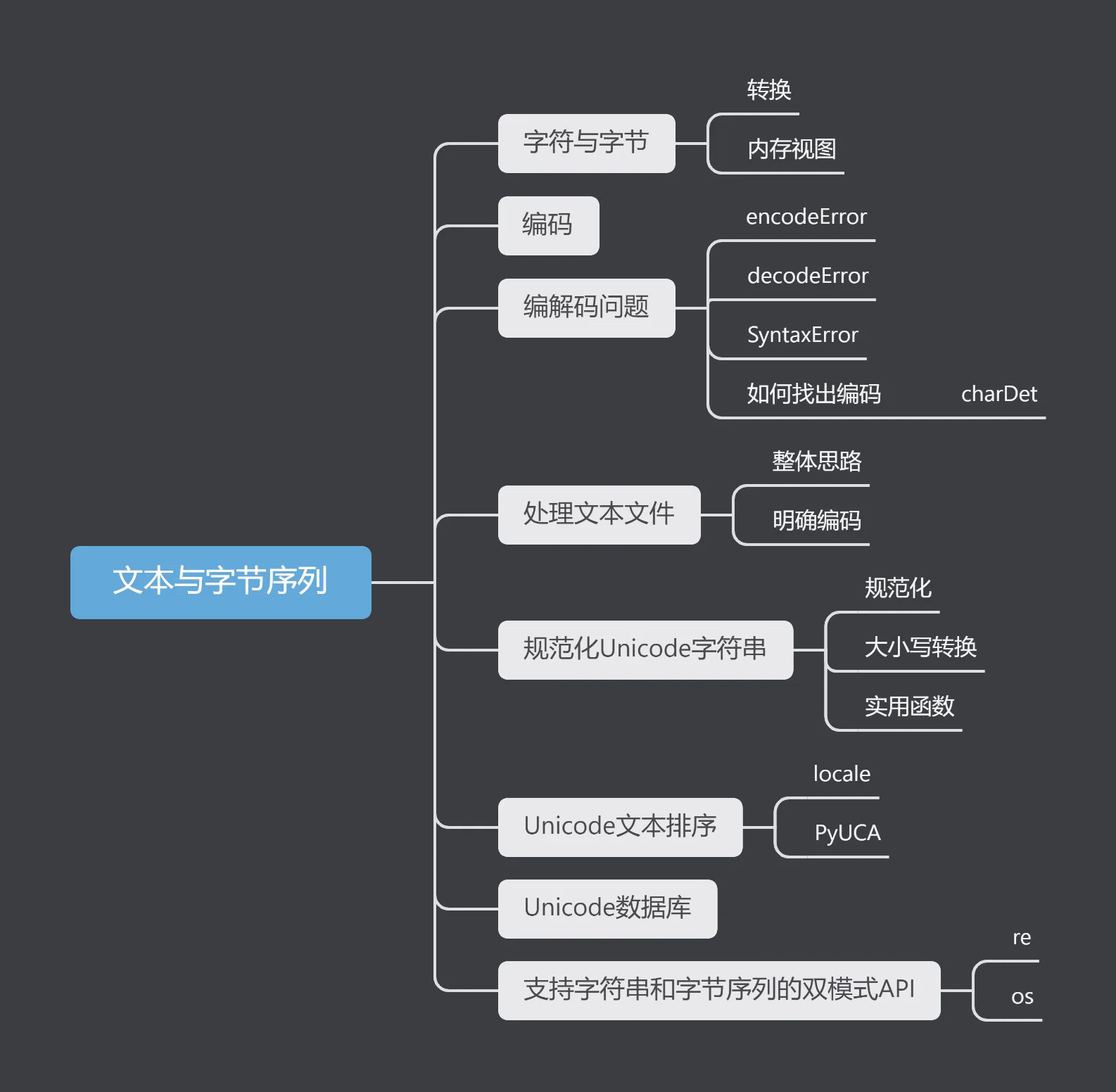
最后附上这部分的思维导图:


文章评论