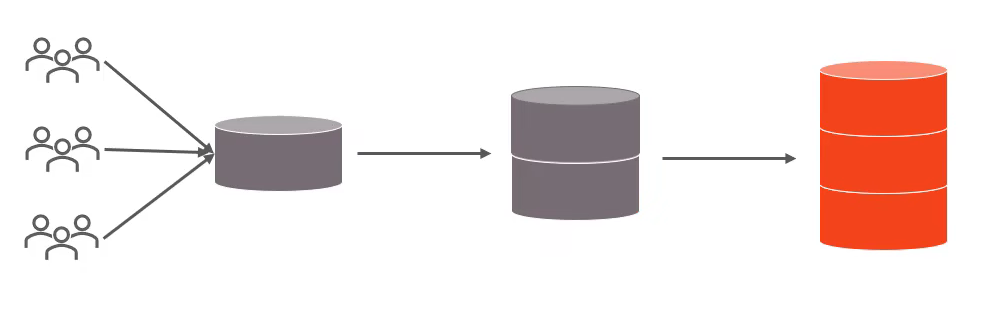
单数据库进行数据存储存在以下瓶颈:
-
-
CPU瓶颈:排序、分组、连接查询、聚合统计等SQL会耗费大量的CPU资源,请求数太多,CPU出现瓶颈。
分库分表的中心思想都是将数据分散存储,使得单一数据库/表的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的:
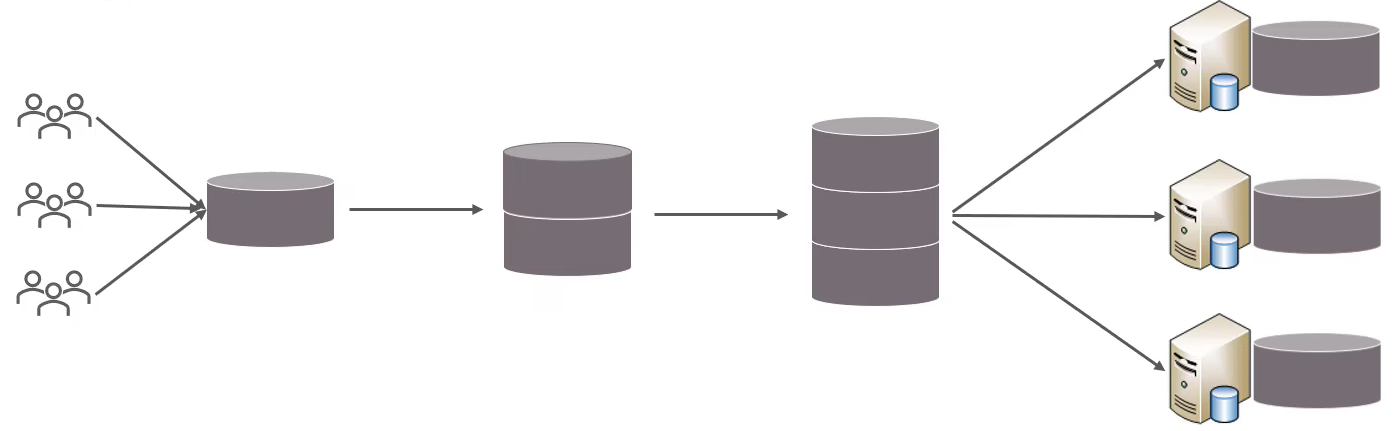
拆分原则
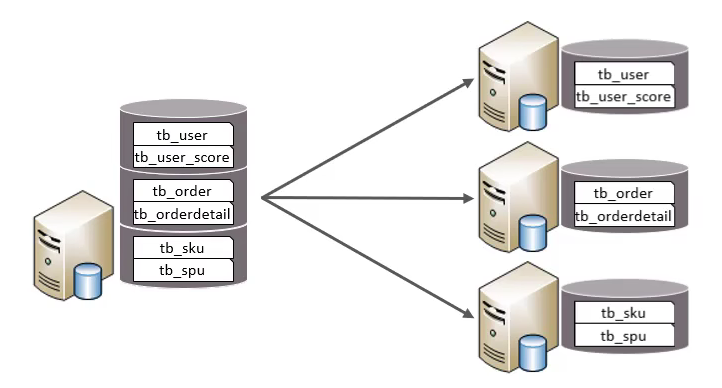
垂直分库
以表为单位,根据业务将不同的表拆分到不同的数据库中。
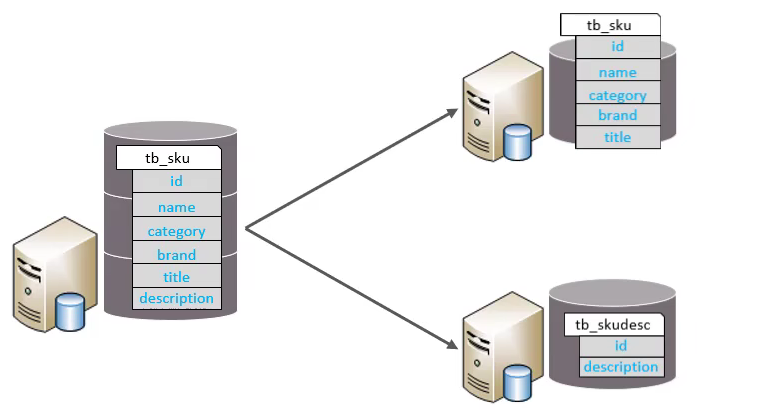
垂直分表
以字段为依据,根据字段属性将不同字段拆分到不同表中。
水平拆分
将一个数据库的数据拆分到多个库中。
MyCat
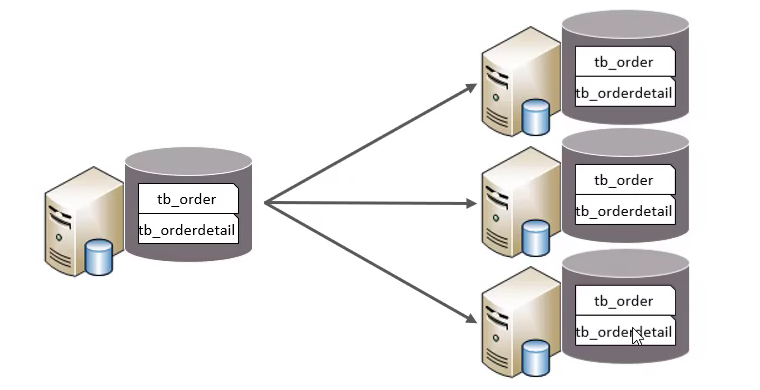
传统的分库分表需要修改应用程序,由程序按照一定规则访问多个数据库:
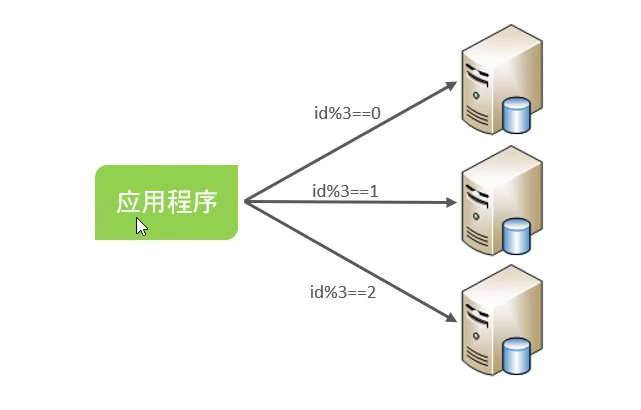
这样会使得应用程序需要编写复杂的 SQL,以及提高业务代码的实现难度。
因此产生了一些用于分库分表的技术,比如 MyCat:
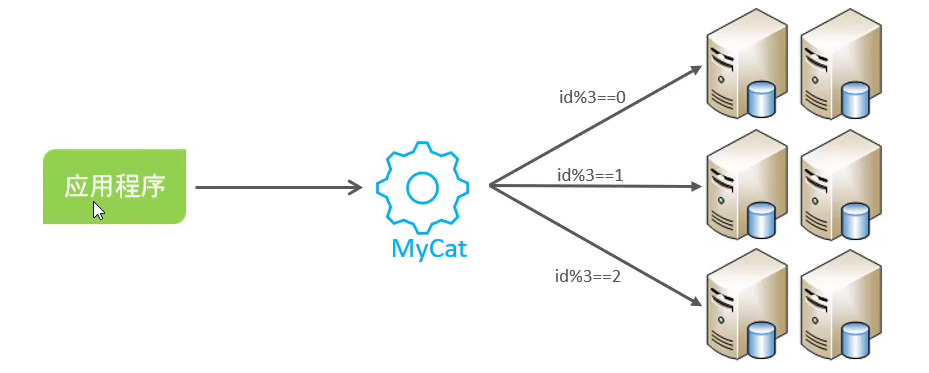
作为分库分表的一个中间件,不需要调整业务代码就可以实现分库分表,支持多种编程语言。
除此之外,还有 shardingJDBC,基于 AOP 原理,在应用程序端对本地执行的 SQL 进行拦截解析和改写,需要自行编码配置实现,只支持 Java 语言,优点是性能较高。
安装
MyCat 是使用 Java 开发的,所以安装 MyCat 前需要先。
从 Github 下载 MyCat1 的安装包。
MyCat2 的官方仓库是。
解压:
sudo tar -zxvf Mycat-server-1.6.7.5-release-20200422133810-linux.tar.gz -C /usr/local/
MyCat 自带的 MySQL 驱动 jar 包(/mycat/lib目录)版本过低:
-rwxrwxrwx. 1 root root 968668 4月 22 2020 mysql-connector-java-5.1.35.jar
拷贝一个更高版本的:
sudo cp /mnt/hgfs/D/download/mysql-connector-java-8.0.30.jar /usr/local/mycat/lib/
修改权限:
sudo chmod 777 mysql-connector-java-8.0.30.jar
删除旧版本:
sudo rm mysql-connector-java-5.1.35.jar
架构
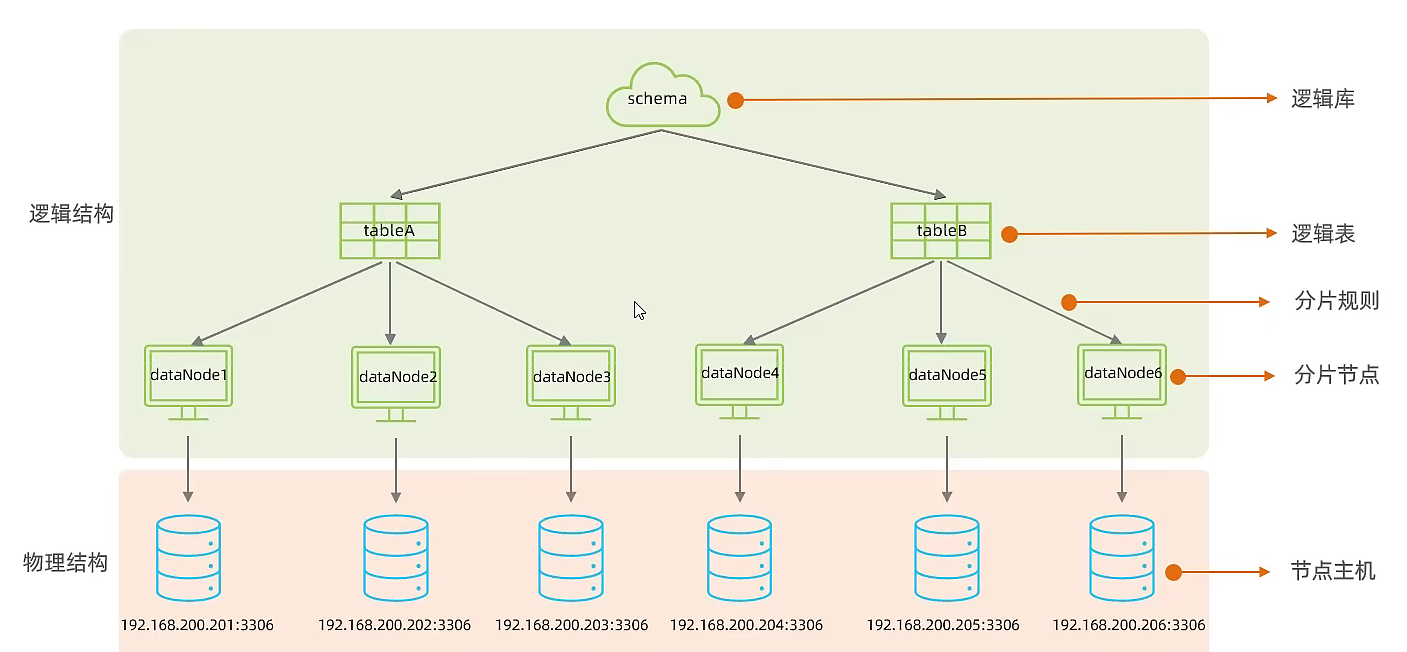
快速入门
配置
需要先确保参与分库分表的数据库都可以被 MyCat 所在的服务器客户端连接,比如在我这个示例中,参与的服务器有:
-
192.168.0.88:部署了 MyCat 和 MySQL
-
192.168.0.46:部署 MySQL
-
192.168.0.133:部署 MySQL
就需要 192.168.0.88 上的 MySQL 客户端可以连接另外两台服务器上的 MySQL 数据库。
如何允许异地连接 MySQL 可以阅读这篇。
如果涉及的数据库配置了主从复制,需要关闭。如何关闭主从复制可以阅读这篇。
还需要确保 Linux 平台的 MySQL 是表名大小写不敏感的,原因和修改方式可以阅读文章。
在三个数据库上都创建一个名为db02的数据库。
配置conf/schema.xml:
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="DB02" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="TB_ORDER" primaryKey="id" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" autoIncrement="true" fetchStoreNodeByJdbc="true">
</table>
</schema>
<dataNode name="dn1" dataHost="dh1" database="db02" />
<dataNode name="dn2" dataHost="dh2" database="db02" />
<dataNode name="dn3" dataHost="dh3" database="db02" />
<dataHost name="dh1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="jdbc:mysql://192.168.0.88:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="icexmoon"
password="Mysql@123">
</writeHost>
</dataHost>
<dataHost name="dh2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="jdbc:mysql://192.168.0.133:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="icexmoon"
password="Mysql@123">
</writeHost>
</dataHost>
<dataHost name="dh3" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="jdbc:mysql://192.168.0.46:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="icexmoon"
password="Mysql@123">
</writeHost>
</dataHost>
</mycat:schema>
建议使用 VSCode 远程连接进行修改。
配置conf/server.xml:
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">DB02</property>
<property name="defaultSchema">TESTDB</property>
</user>
<user name="user">
<property name="password">123456</property>
<property name="schemas">DB02</property>
<property name="readOnly">true</property>
<property name="defaultSchema">TESTDB</property>
</user>
root 账户可读可写,user 账户只读。
添加环境变量:
vim /etc/profile
添加:
export MYCAT_HOME=/usr/local/mycat
启动
MyCat 使用 8066 端口,因此启动前还需要开放 8066 端口,如何配置防火墙以开放端口可以阅读文章。
还需要为日志输出创建目录,MyCat 不会自动创建该目录:
mkdir logs
chmod 777 logs
启动 MyCat:
cd /usr/local/mycat/
bin/mycat console
mycat console是从前台启动,会将启动日志输出到控制台,有助于问题排查,因此第一次启动建议通过这种方式。
如果启动成功,可以看到MyCAT Server startup successfully.字样。
之后再启动就可以通过mycat start的方式后台启动。
通过以下命令可以查看运行状态:
bin/mycat status
Mycat-server is running (88681).
错误排查
生成的错误日志文件在logs/wrapper.log。可以通过查看该文件分析错误,也可以直接通过mycat console前台启动的方式查看启动时产生的错误信息。
如果启动失败,显示的日志信息中有Error: Could not create the Java Virtual Machine.这样的字样,可能是因为 JVM 内存不足导致,需要修改配置文件/conf/wrapper.conf:
# 最大堆内存(建议不超过物理内存的70%)
wrapper.java.additional.9=-Xmx2G
# 初始堆内存(建议1G-2G)
wrapper.java.additional.10=-Xms1G
如果日志中的错误信息包含Unrecognized VM option 'AggressiveOpts',是因为官方建议使用 JDK 8,你使用了更高的版本,而在高版本 JDK 中AggressiveOpts是一个无效参数,因此需要修改(同一个)配置文件:
# wrapper.java.additional.3=-XX:+AggressiveOpts
如果错误日志中出现下面的内容:
java.lang.IllegalAccessError: class io.mycat.buffer.ByteBufferPage (in unnamed module @0x6e2c634b) cannot access class sun.nio.ch.DirectBuffer (in module java.base) because module java.base does not export sun.nio.ch to unnamed module @0x6e2c634b
这是因为在高版本 JDK 中,官方包(比如这里的 java.base)不允许随便引用,因此需要通过在配置文件中添加 JDK 参数开放相应的官方包给 MyCat:
wrapper.java.additional.3=--add-exports=java.base/sun.nio.ch=ALL-UNNAMED
如果错误日志出现如下内容:
Running Mycat-server... wrapper | --> Wrapper Started as Console Unable to open logfile logs/wrapper.log: Permission denied
说明缺少写入日志的权限,可以尝试使用sudo ./mycat start启动。
如果错误日志出现如下内容:
Running Mycat-server... wrapper | --> Wrapper Started as Console wrapper | Launching a JVM... wrapper | JVM exited while loading the application. jvm 1 | wrapper | Unable to start JVM: No such file or directory (2)
这似乎是一个 bug,如果激活了某些分片算法,就可能导致这个问题出现,默认 MyCat 会运行 java 命令使用 JDK,如果出现这个错误提示,就表示某些代码通过这种方式不能正常启动 JVM,可以尝试修改配置文件conf/wrapper.conf,指定 JDK 的绝对位置来修复这个问题:
wrapper.java.command=/usr/lib/jvm/jdk22/bin/java
使用
可以像使用普通的 MySQL 服务器那样使用 MyCat,连接 MyCat:
mysql -h192.168.0.88 -uroot -P8066 -p
注意,即使是本地而非异地连接,也必须要指定 ip,否则无法连接。大概是在 MyCat 中将所有账户视为 xxx@%,并不存在 xxx@localhost 这样的帐号。
查看 MyCat 中配置的逻辑库和逻辑表:
mysql> show databases;
+----------+
| DATABASE |
+----------+
| DB02 |
+----------+
mysql> use DB02;
mysql> show tables;
+----------------+
| Tables in DB02 |
+----------------+
| tb_order |
+----------------+
这个逻辑表只是一个空壳,实际上并没有在三个物理 MySQL 数据库上有表结构和数据。
通过 MyCat 为这个逻辑表创建表结构:
mysql> create table TB_ORDER(
-> id bigint(20) not null,
-> title varchar(100) not null,
-> primary key (id)
-> ) engine=innodb default charset=utf8;
如果查看各个数据库,可以看到这张表在各个数据库上已经生成。
如果使用 DataGrid 查看,需要刷新。
插入三条数据:
mysql> insert into TB_ORDER(id,title) values(1,'goods1');
Query OK, 1 row affected (0.03 sec)
OK!
mysql> insert into TB_ORDER(id,title) values(2,'goods2');
Query OK, 1 row affected (0.03 sec)
OK!
mysql> insert into TB_ORDER(id,title) values(3,'goods3');
Query OK, 1 row affected (0.03 sec)
OK!
会发现三条数据都插入到了同一个物理数据库中。
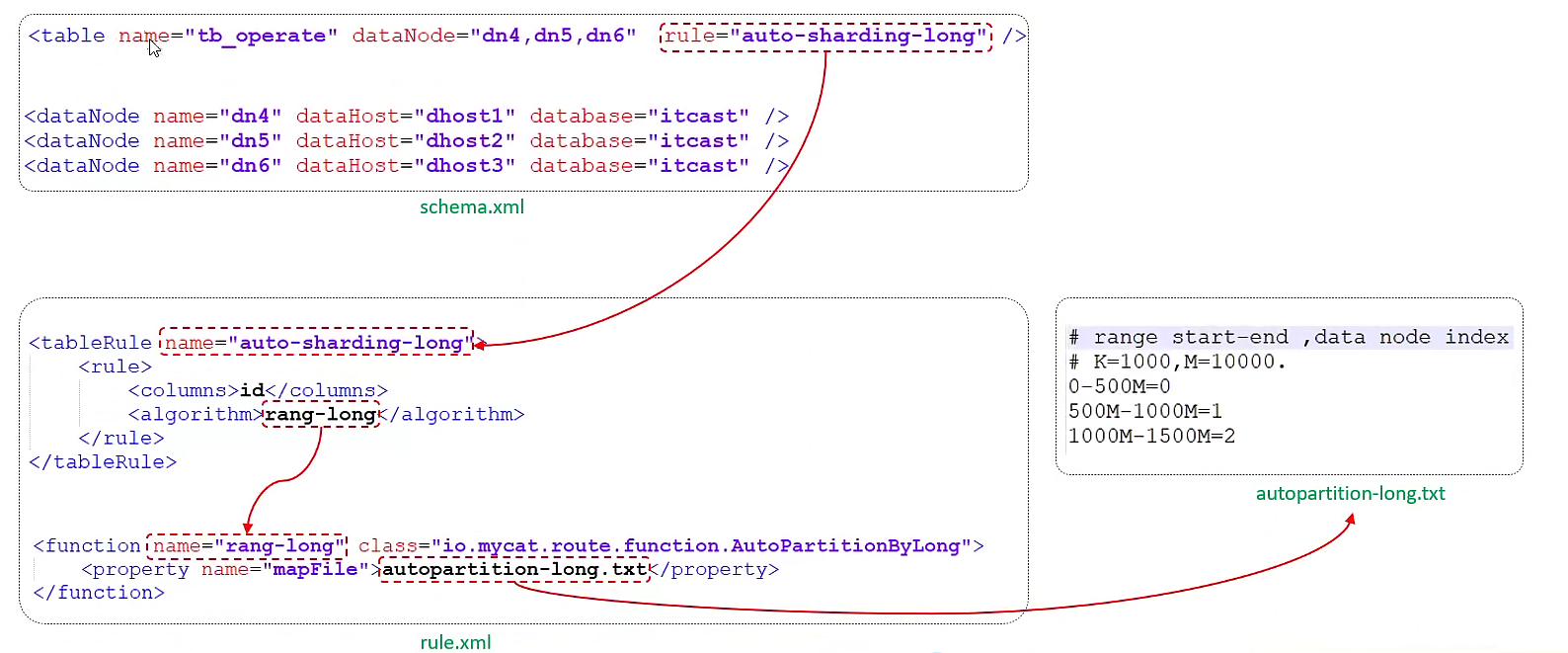
这是因为在配置文件schemal.xml中定义了该逻辑表的分片规则:
<table name="TB_ORDER" primaryKey="id" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" autoIncrement="true" fetchStoreNodeByJdbc="true">
</table>
这里的auto-sharding-long是规则配置文件rule.xml中的一个预定义规则:
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
这个规则实际上由range-long规则决定:
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
该规则的分片依据写在autopartition-long.txt文件中:
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0
500M-1000M=1
1000M-1500M=2
这三条规则表示:
-
0~500万的数据记录在编号为0的节点
-
500万~1000万的数据记录在编号为1的节点
-
1000万~1500万的数据记录在编号为2的节点
可以通过插入一下数据观察规则是否如此:
mysql> insert into TB_ORDER(id,title) values(5000000,'goods');
Query OK, 1 row affected (0.04 sec)
OK!
mysql> insert into TB_ORDER(id,title) values(5000001,'goods');
Query OK, 1 row affected (0.04 sec)
OK!
mysql> insert into TB_ORDER(id,title) values(10000000,'goods');
Query OK, 1 row affected (0.04 sec)
OK!
mysql> insert into TB_ORDER(id,title) values(10000001,'goods');
Query OK, 1 row affected (0.03 sec)
OK!
需要注意的是,如果超过规则边界(1500万),数据插入会失败:
mysql> insert into TB_ORDER(id,title) values(15000001,'goods');
ERROR 1064 (HY000): can't find any valid datanode :TB_ORDER -> ID -> 15000001
此时需要添加新的节点(扩容)。
配置
schema.xml
主要包含逻辑库逻辑表等配置信息。
schema
<schema name="DB02" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<! ... -->
</schema>
schema 标签用于定义 逻辑库,一个 MyCat 实例中,可以定义多个逻辑库。逻辑库相当于 MySQL 的 database。可以通过use xxx命令切换不同的逻辑库。
主要包含以下属性:
-
name,逻辑库名
-
checkSQLschema,执行 SQL 时如果指定了数据库名,是否自动去除
-
sqlMaxLimit,如果查询时没有指定 limit,最多返回的数据条数
table
<table name="TB_ORDER" primaryKey="id" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" autoIncrement="true" fetchStoreNodeByJdbc="true">
</table>
定义逻辑库下的逻辑表,包含以下属性:
-
name,逻辑表名称,在逻辑库中唯一
-
dataNode,逻辑表所属dataNode
-
rule,,分片规则名称,由 rule.xml 定义
-
primaryKey,逻辑表对应真实表的主键
-
type,逻辑表类型,如果未配置就是普通表,会被分片。global 表示全局表,不会分片,每个节点保存一份
dataNode
<dataNode name="dn1" dataHost="dh1" database="db02" />
属性:
-
name,数据节点名称
-
dataHost,数据库实例
-
database,分片对应的数据库名
dataHost
<dataHost name="dh1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="jdbc:mysql://192.168.0.88:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="icexmoon"
password="Mysql@123">
</writeHost>
</dataHost>
属性:
-
name,唯一标识
-
maxCon/minCon,最大连接数/最小连接数
-
balance,负载均衡策略,取值 0,1,2,3
-
writeType,写操作分发方式(0:转发到第一个 writeHost,如果挂了,切换到第二个。1:写操作随机分发到配置的 writeHost)
-
dbDriver,数据库驱动,支持 native,JDBC
rule.xml
tableRule
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
对表进行分片时使用的规则,包含以下子节点:
-
columns,规则依据的列
-
algorithm,分片算法
function
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
分片规则使用的分片算法。
属性:
-
name,算法名称
-
class,算法的 Java 实现类
property 节点中包含算法相关的属性,可以是一个配置文件。
server.xml
system
该标签下的子标签property定义了 MyCat 运行时的行为,相当于其他应用的配置文件。
包括以下属性:
| 属性 | 取值 | 含义 |
|---|---|---|
| charset | utf8 | 设置Mycat的字符集, 字符集需要与MySQL的字符集保持一致 |
| nonePasswordLogin | 0,1 | 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户 |
| useHandshakeV10 | 0,1 | 使用该选项主要的目的是为了能够兼容高版本的jdbc驱动, 是否采用HandshakeV10Packet来与client进行通信, 1:是, 0:否 |
| useSqlStat | 0,1 | 开启SQL实时统计, 1 为开启 , 0 为关闭 ; 开启之后, MyCat会自动统计SQL语句的执行情况 ; mysql -h 127.0.0.1 -P 9066 -u root -p 查看MyCat执行的SQL, 执行效率比较低的SQL , SQL的整体执行情况、读写比例等 ; show @@sql ; show @@sql.slow ; show @@sql.sum ; |
| useGlobleTableCheck | 0,1 | 是否开启全局表的一致性检测。1为开启 ,0为关闭 。 |
| sqlExecuteTimeout | 1000 | SQL语句执行的超时时间 , 单位为 s ; |
| sequnceHandlerType | 0,1,2 | 用来指定Mycat全局序列类型,0 为本地文件,1 为数据库方式,2 为时间戳列方式,默认使用本地文件方式,文件方式主要用于测试 |
| sequnceHandlerPattern | 正则表达式 | 必须带有MYCATSEQ或者 mycatseq进入序列匹配流程 注意MYCATSEQ_有空格的情况 |
| subqueryRelationshipCheck | true,false | 子查询中存在关联查询的情况下,检查关联字段中是否有分片字段 .默认 false |
| useCompression | 0,1 | 开启mysql压缩协议 , 0 : 关闭, 1 : 开启 |
| fakeMySQLVersion | 5.5,5.6 | 设置模拟的MySQL版本号 |
| defaultSqlParser | 由于MyCat的最初版本使用了FoundationDB的SQL解析器, 在MyCat1.3后增加了Druid解析器, 所以要设置defaultSqlParser属性来指定默认的解析器; 解析器有两个 : druidparser 和 fdbparser, 在MyCat1.4之后,默认是druidparser, fdbparser已经废除了 | |
| processors | 1,2.... | 指定系统可用的线程数量, 默认值为CPU核心 x 每个核心运行线程数量; processors 会影响processorBufferPool, processorBufferLocalPercent, processorExecutor属性, 所有, 在性能调优时, 可以适当地修改processors值 |
| processorBufferChunk | 指定每次分配Socket Direct Buffer默认值为4096字节, 也会影响BufferPool长度, 如果一次性获取字节过多而导致buffer不够用, 则会出现警告, 可以调大该值 | |
| processorExecutor | 指定NIOProcessor上共享 businessExecutor固定线程池的大小; MyCat把异步任务交给 businessExecutor线程池中, 在新版本的MyCat中这个连接池使用频次不高, 可以适当地把该值调小 | |
| packetHeaderSize | 指定MySQL协议中的报文头长度, 默认4个字节 | |
| maxPacketSize | 指定MySQL协议可以携带的数据最大大小, 默认值为16M | |
| idleTimeout | 30 | 指定连接的空闲时间的超时长度;如果超时,将关闭资源并回收, 默认30分钟 |
| txIsolation | 1,2,3,4 | 初始化前端连接的事务隔离级别,默认为 REPEATED_READ , 对应数字为3 READ_UNCOMMITED=1; READ_COMMITTED=2; REPEATED_READ=3; SERIALIZABLE=4; |
| sqlExecuteTimeout | 300 | 执行SQL的超时时间, 如果SQL语句执行超时,将关闭连接; 默认300秒; |
| serverPort | 8066 | 定义MyCat的使用端口, 默认8066 |
| managerPort | 9066 | 定义MyCat的管理端口, 默认9066 |
user
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">DB02</property>
<property name="defaultSchema">TESTDB</property>
<!--No MyCAT Database selected 错误前会尝试使用该schema作为schema,不设置则为null,报错 -->
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
设置 MyCat 用户和权限。
示例,修改 root 用户的权限:
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">DB02</property>
<property name="defaultSchema">TESTDB</property>
<privileges check="true">
<schema name="DB02" dml="0110" >
<table name="TB_ORDER" dml="1110"></table>
</schema>
</privileges>
</user>
这里的 dml 属性是用二进制表示权限 IUSD(增改查删),如果逻辑库和逻辑表都设置了权限,遵循就近原则,即逻辑表的权限生效。
重启 MyCat 以使权限生效:
mycat restart
测试权限设置:
mysql> insert into TB_ORDER(id,title) values(6,'goods');
ERROR 2013 (HY000): Lost connection to MySQL server during query
No connection. Trying to reconnect...
Connection id: 1
Current database: DB02
Query OK, 1 row affected (0.66 sec)
OK!
mysql> update TB_ORDER set title='goods2' where id=1;
Query OK, 1 row affected (0.14 sec)
OK!
mysql> select * from TB_ORDER where id=1;
+------+--------+
| ID | TITLE |
+------+--------+
| 1 | goods2 |
+------+--------+
1 row in set (0.05 sec)
mysql> delete from TB_ORDER WHERE id=1;
ERROR 3012 (HY000): The statement DML privilege check is not passed, reject for user 'root'
垂直拆分
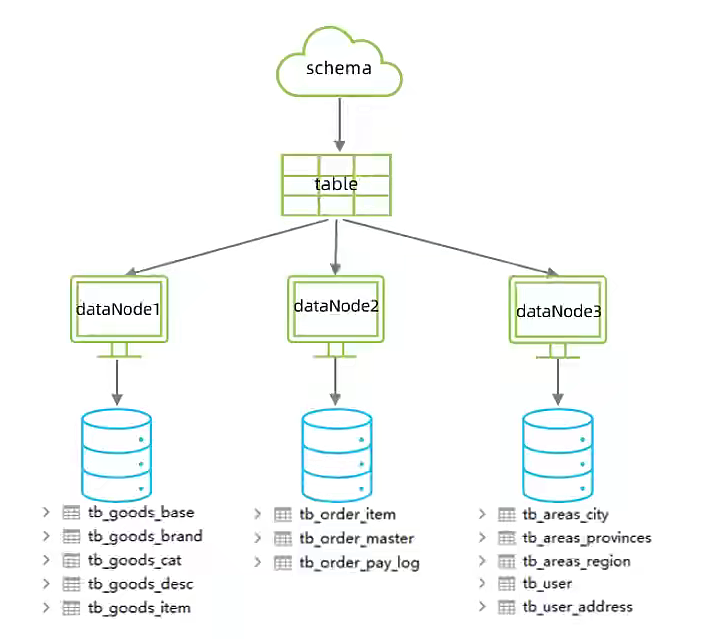
先在三台 MySQL 上创建数据库shopping。
修改配置文件,添加 schema 定义:
<schema name="SHOPPING" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="tb_goods_base" primaryKey="id" dataNode="dn4"/>
<table name="tb_goods_brand" primaryKey="id" dataNode="dn4"/>
<table name="tb_goods_cat" primaryKey="id" dataNode="dn4"/>
<table name="tb_goods_desc" primaryKey="goods_id" dataNode="dn4"/>
<table name="tb_goods_item" primaryKey="id" dataNode="dn4"/>
<table name="tb_order_item" primaryKey="id" dataNode="dn5"/>
<table name="tb_order_master" primaryKey="order_id" dataNode="dn5"/>
<table name="tb_order_pay_log" primaryKey="out_trade_no" dataNode="dn5"/>
<table name="tb_user" primaryKey="id" dataNode="dn6"/>
<table name="tb_user_address" primaryKey="id" dataNode="dn6"/>
<table name="tb_areas_provinces" primaryKey="id" dataNode="dn6"/>
<table name="tb_areas_city" primaryKey="id" dataNode="dn6"/>
<table name="tb_areas_region" primaryKey="id" dataNode="dn6"/>
</schema>
添加对应的 dataNode 定义:
<dataNode name="dn4" dataHost="dh1" database="shopping" />
<dataNode name="dn5" dataHost="dh2" database="shopping" />
<dataNode name="dn6" dataHost="dh3" database="shopping" />
这样用户是访问不到的,还需要在用户配置中关联逻辑库:
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">DB02,SHOPPING</property>
<property name="defaultSchema">SHOPPING</property>
</user>
使用客户端连接 MyCat 后查看:
mysql> show databases;
+----------+
| DATABASE |
+----------+
| DB02 |
| SHOPPING |
+----------+
导入数据:
mysql> source /home/icexmoon/download/sql/shopping-table.sql;
mysql> source /home/icexmoon/download/sql/shopping-insert.sql;
上述 SQL 文件可以从获取。
这种垂直拆分以后有个问题,如果是联表查询,涉及的表在同一个数据节点(Data Node):
select ua.USER_ID,ua.CONTACT,p.PROVINCE,c.CITY,r.AREA,ua.ADDRESS
from tb_user_address ua,tb_areas_provinces p,tb_areas_city c,tb_areas_region r
where ua.PROVINCE_ID=p.PROVINCEID and ua.CITY_ID=c.CITYID and ua.TOWN_ID=r.AREAID;
在 MyCat 中是可以正常执行并返回结果的。
但如果联表查询涉及的表在不同数据节点:
select om.ORDER_ID,om.PAYMENT,om.USER_ID,om.RECEIVER,p.PROVINCE,c.CITY,r.AREA
from tb_order_master om,tb_areas_provinces p,tb_areas_city c,tb_areas_region r
where om.RECEIVER_PROVINCE=p.PROVINCEID and om.RECEIVER_CITY=c.CITYID and om.RECEIVER_REGION=r.AREAID;
会导致查询失败:
ERROR 1064 (HY000): invalid route in sql, multi tables found but datanode has no intersection sql:select om.ORDER_ID,om.PAYMENT,om.USER_ID,om.RECEIVER,p.PROVINCE,c.CITY,r.AREA
from tb_order_master om,tb_areas_provinces p,tb_areas_city c,tb_areas_region r
where om.RECEIVER_PROVINCE=p.PROVINCEID and om.RECEIVER_CITY=c.CITYID and om.RECEIVER_REGION=r.AREAID
因为 MyCat 在具体执行的时候,需要将 SQL 路由到一个数据节点执行,但这里的 SELECT 语句涉及的表结构一部分在节点2,一部分在节点3,MyCat 就会报路由错误。
这种情况可以通过将省市区这种数据量少且多个节点都要联表查询的表设置为全局表来解决。
修改 MyCat 配置,将上述字典表设置为全局表:
<table name="tb_areas_provinces" primaryKey="id" dataNode="dn4,dn5,dn6" type="global"/>
<table name="tb_areas_city" primaryKey="id" dataNode="dn4,dn5,dn6" type="global"/>
<table name="tb_areas_region" primaryKey="id" dataNode="dn4,dn5,dn6" type="global"/>
关闭 MyCat:
./mycat stop
删除三台 MySQL 上的 shopping 库中的所有表。
启动 MyCat:
./mycat start
重新通过 MyCat 导入表结构和数据:
mysql> source /home/icexmoon/download/sql/shopping-table.sql
mysql> source /home/icexmoon/download/sql/shopping-insert.sql
可以看到,每个数据节点都包含了三张全局表,且都拥有相同的数据。
此时再通过 MyCat 执行之前的查询语句:
select om.ORDER_ID,om.PAYMENT,om.USER_ID,om.RECEIVER,p.PROVINCE,c.CITY,r.AREA
from tb_order_master om,tb_areas_provinces p,tb_areas_city c,tb_areas_region r
where om.RECEIVER_PROVINCE=p.PROVINCEID and om.RECEIVER_CITY=c.CITYID and om.RECEIVER_REGION=r.AREAID;
可以正常查询到结果。
如果通过 MyCat 对全局表进行更新操作:
mysql> select * from tb_areas_provinces where id=1;
+------+------------+-----------+
| ID | PROVINCEID | PROVINCE |
+------+------------+-----------+
| 1 | 110000 | 北京市 |
+------+------------+-----------+
1 row in set (0.01 sec)
mysql> update tb_areas_provinces set province='北京' where id=1;
Query OK, 1 row affected (0.15 sec)
OK!
mysql> select * from tb_areas_provinces where id=1;
+------+------------+----------+
| ID | PROVINCEID | PROVINCE |
+------+------------+----------+
| 1 | 110000 | 北京 |
+------+------------+----------+
查看三台 MySQL 你会发现,所有的 tb_areas_provinces 表中的数据都发生了改变。
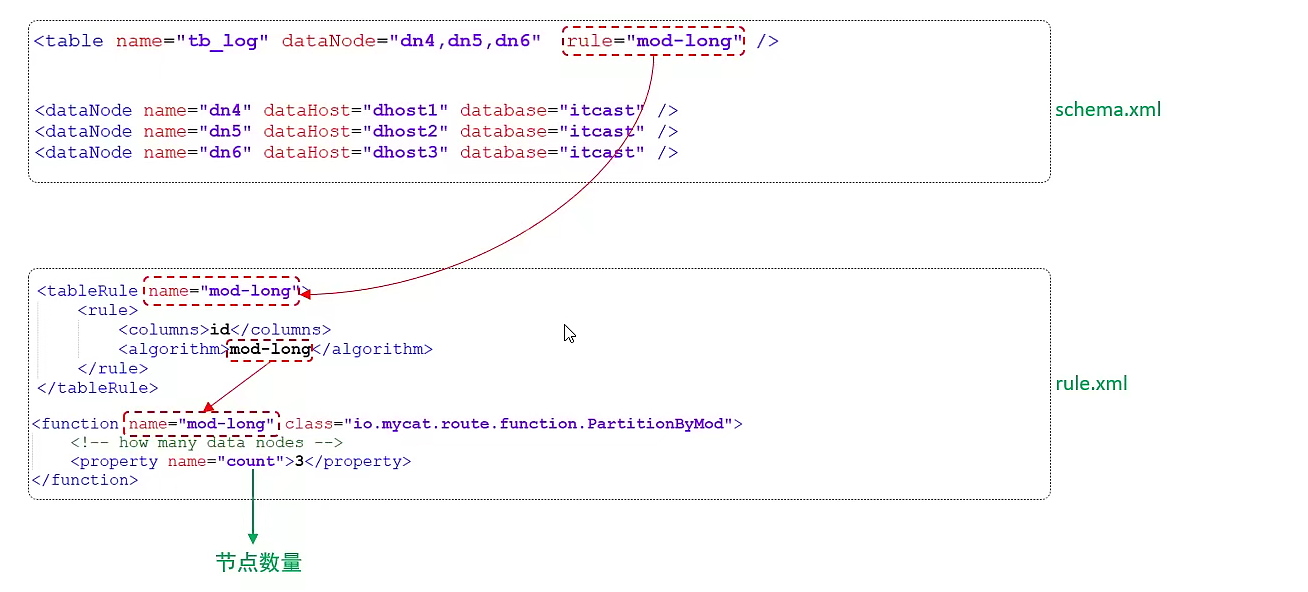
水平分表
在三台 MySQL 上创建名为db03的数据库。
修改配置文件,添加逻辑库和逻辑表定义:
<schema name="DB03" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="tb_log" primaryKey="id" dataNode="dn7,dn8,dn9" rule="mod-long"/>
</schema>
<dataNode name="dn7" dataHost="dh1" database="db03" />
<dataNode name="dn8" dataHost="dh2" database="db03" />
<dataNode name="dn9" dataHost="dh3" database="db03" />
这里使用的分片规则是mod-long,而非之前使用的auto-sharding-rang-mod,前者根据主键模运算的结果进行分片,后者是范围分片,通过模运算分片可以让数据分片更为均匀。
不要忘了修改用户权限,否则无法操作新增的逻辑表:
<property name="schemas">DB02,SHOPPING,DB03</property>
重启 MyCat:
./mycat restart
执行 SQL 创建表结构与插入数据:
use DB03;
CREATE TABLE tb_log (
id bigint(20) NOT NULL COMMENT 'ID',
model_name varchar(200) DEFAULT NULL COMMENT '模块名',
model_value varchar(200) DEFAULT NULL COMMENT '模块值',
return_value varchar(200) DEFAULT NULL COMMENT '返回值',
return_class varchar(200) DEFAULT NULL COMMENT '返回值类型',
operate_user varchar(20) DEFAULT NULL COMMENT '操作用户',
operate_time varchar(20) DEFAULT NULL COMMENT '操作时间',
param_and_value varchar(500) DEFAULT NULL COMMENT '请求参数名及参数值',
operate_class varchar(200) DEFAULT NULL COMMENT '操作类',
operate_method varchar(200) DEFAULT NULL COMMENT '操作方法',
cost_time bigint(20) DEFAULT NULL COMMENT '执行方法耗时, 单位 ms',
source int(1) DEFAULT NULL COMMENT '来源 : 1 PC , 2 Android , 3 IOS',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO tb_log (id, model_name, model_value, return_value, return_class, operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source) VALUES('1','user','insert','success','java.lang.String','10001','2022-01-06 18:12:28','{\"age\":\"20\",\"name\":\"Tom\",\"gender\":\"1\"}','cn.itcast.controller.UserController','insert','10',1);
INSERT INTO tb_log (id, model_name, model_value, return_value, return_class, operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source) VALUES('2','user','insert','success','java.lang.String','10001','2022-01-06 18:12:27','{\"age\":\"20\",\"name\":\"Tom\",\"gender\":\"1\"}','cn.itcast.controller.UserController','insert','23',1);
INSERT INTO tb_log (id, model_name, model_value, return_value, return_class, operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source) VALUES('3','user','update','success','java.lang.String','10001','2022-01-06 18:16:45','{\"age\":\"20\",\"name\":\"Tom\",\"gender\":\"1\"}','cn.itcast.controller.UserController','update','34',1);
INSERT INTO tb_log (id, model_name, model_value, return_value, return_class, operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source) VALUES('4','user','update','success','java.lang.String','10001','2022-01-06 18:16:45','{\"age\":\"20\",\"name\":\"Tom\",\"gender\":\"1\"}','cn.itcast.controller.UserController','update','13',2);
INSERT INTO tb_log (id, model_name, model_value, return_value, return_class, operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source) VALUES('5','user','insert','success','java.lang.String','10001','2022-01-06 18:30:31','{\"age\":\"200\",\"name\":\"TomCat\",\"gender\":\"0\"}','cn.itcast.controller.UserController','insert','29',3);
INSERT INTO tb_log (id, model_name, model_value, return_value, return_class, operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source) VALUES('6','user','find','success','java.lang.String','10001','2022-01-06 18:30:31','{\"age\":\"200\",\"name\":\"TomCat\",\"gender\":\"0\"}','cn.itcast.controller.UserController','find','29',2);
可以看到数据的确根据主键取模进行了分片。
分片规则
范围分片
如果用于分片的列是整数,就可以按照范围进行分片。
取模分片
如果用于分片的列是整数,也可以通过模运算进行分片。
一致性 hash
相同的 hash 因子计算值总是被哈芬到相同的数据节点,不会因为分区节点的增加而改变原来数据的分区位置。
如果表的主键不是 int(比如 uuid),就可以使用这种规则进行分片。
示例
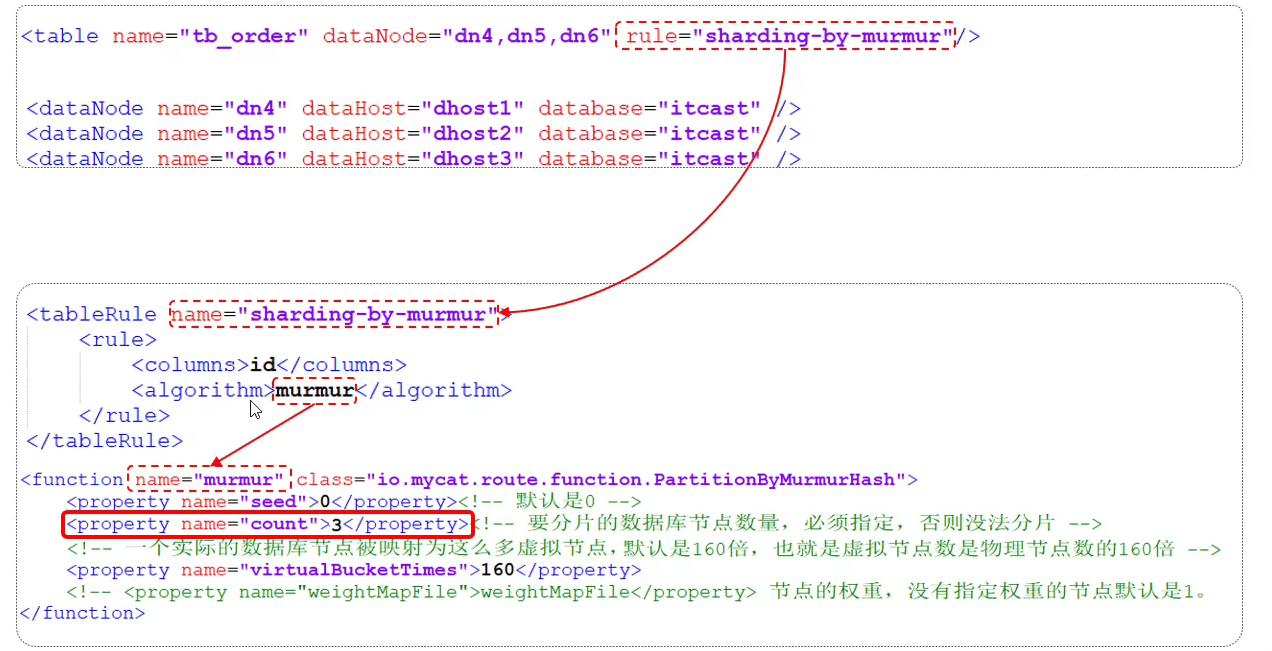
添加一个逻辑表:
<schema name="DB03" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="tb_order" dataNode="dn7,dn8,dn9" rule="sharding-by-murmur"/>
</schema>
默认的分片规则使用 2 个数据节点,我们这里使用 3 个,因此需要修改规则配置文件:
<function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">3</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
</function>
重启 MyCat。
通过 MyCat 导入表结构和数据:
create table tb_order(
id varchar(100) not null primary key,
money int null,
content varchar(200) null
);
INSERT INTO tb_order (id, money, content) VALUES ('b92fdaaf-6fc4-11ec-b831-482ae33c4a2d', 10, 'b92fdaf8-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b93482b6-6fc4-11ec-b831-482ae33c4a2d', 20, 'b93482d5-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b937e246-6fc4-11ec-b831-482ae33c4a2d', 50, 'b937e25d-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b93be2dd-6fc4-11ec-b831-482ae33c4a2d', 100, 'b93be2f9-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b93f2d68-6fc4-11ec-b831-482ae33c4a2d', 130, 'b93f2d7d-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b9451b98-6fc4-11ec-b831-482ae33c4a2d', 30, 'b9451bcc-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b9488ec1-6fc4-11ec-b831-482ae33c4a2d', 560, 'b9488edb-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b94be6e6-6fc4-11ec-b831-482ae33c4a2d', 10, 'b94be6ff-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b94ee10d-6fc4-11ec-b831-482ae33c4a2d', 123, 'b94ee12c-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b952492a-6fc4-11ec-b831-482ae33c4a2d', 145, 'b9524945-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b95553ac-6fc4-11ec-b831-482ae33c4a2d', 543, 'b95553c8-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b9581cdd-6fc4-11ec-b831-482ae33c4a2d', 17, 'b9581cfa-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b95afc0f-6fc4-11ec-b831-482ae33c4a2d', 18, 'b95afc2a-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b95daa99-6fc4-11ec-b831-482ae33c4a2d', 134, 'b95daab2-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b9667e3c-6fc4-11ec-b831-482ae33c4a2d', 156, 'b9667e60-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b96ab489-6fc4-11ec-b831-482ae33c4a2d', 175, 'b96ab4a5-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b96e2942-6fc4-11ec-b831-482ae33c4a2d', 180, 'b96e295b-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b97092ec-6fc4-11ec-b831-482ae33c4a2d', 123, 'b9709306-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b973727a-6fc4-11ec-b831-482ae33c4a2d', 230, 'b9737293-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b978840f-6fc4-11ec-b831-482ae33c4a2d', 560, 'b978843c-6fc4-11ec-b831-482ae33c4a2d');
枚举分片
如果用于分片的列是枚举值(比如状态、性别等),就可以配置根据枚举值进行分片。

示例
这里我们要分片的目标表:
CREATE TABLE tb_user (
id bigint(20) NOT NULL COMMENT 'ID',
username varchar(200) DEFAULT NULL COMMENT '姓名',
status int(2) DEFAULT '1' COMMENT '1: 未启用, 2: 已启用, 3: 已关闭',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
要针对 status 字段进行枚举分片,因为默认的枚举规则针对 id 字段进行分片,所以这里创建新的枚举规则:
<tableRule name="sharding-by-intfile-status">
<rule>
<columns>status</columns>
<algorithm>hash-int-status</algorithm>
</rule>
</tableRule>
<function name="hash-int-status"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int-status.txt</property>
</function>
分片规则文件partition-hash-int-status.txt:
1=0
2=1
3=2
这个文件意味着 status=1 的会分到第一个节点,status=2 的会分到第二个节点,以此类推。
规则创建好了,创建使用该规则的逻辑表:
<schema name="DB03" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="tb_user" dataNode="dn7,dn8,dn9" rule="sharding-by-intfile-status"/>
</schema>
重启 MyCat。
导入数据:
CREATE TABLE tb_user (
id bigint(20) NOT NULL COMMENT 'ID',
username varchar(200) DEFAULT NULL COMMENT '姓名',
status int(2) DEFAULT '1' COMMENT '1: 未启用, 2: 已启用, 3: 已关闭',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into tb_user (id,username ,status) values(1,'Tom',1);
insert into tb_user (id,username ,status) values(2,'Cat',2);
insert into tb_user (id,username ,status) values(3,'Rose',3);
insert into tb_user (id,username ,status) values(4,'Coco',2);
insert into tb_user (id,username ,status) values(5,'Lily',1);
insert into tb_user (id,username ,status) values(6,'Tom',1);
insert into tb_user (id,username ,status) values(7,'Cat',2);
insert into tb_user (id,username ,status) values(8,'Rose',3);
insert into tb_user (id,username ,status) values(9,'Coco',2);
insert into tb_user (id,username ,status) values(10,'Lily',1);
可以看到数据按照 status 被分布在不同的数据节点。
需要注意的是,如果插入的数据超过枚举值的设定,比如:
mysql> insert into tb_user (id,username,status) values(11,'Tom',4);
ERROR 1064 (HY000): can't find any valid datanode :TB_USER -> STATUS -> 4
会报错,无法插入。
因此使用枚举分片时,最好为分片规则制定一个默认节点:
<function name="hash-int-status"
class="io.mycat.route.function.PartitionByFileMap">
<property name="defaultNode">2</property>
<property name="mapFile">partition-hash-int-status.txt</property>
</function>
这里配置了如果没有匹配的枚举值,就使用节点 2 作为默认节点进行存储。
重启 MyCat。
现在再执行 sql 就能看到数据被插入节点2。
应用指定
可以在插入数据时,使用某个字段或者某个字段的子字符串指定让数据存储到哪个分片。

示例
要分片的目标表和数据:
CREATE TABLE tb_app (
id varchar(10) NOT NULL COMMENT 'ID',
name varchar(200) DEFAULT NULL COMMENT '名称',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into tb_app (id,name) values('0000001','Testx00001');
insert into tb_app (id,name) values('0100001','Test100001');
insert into tb_app (id,name) values('0100002','Test200001');
insert into tb_app (id,name) values('0200001','Test300001');
insert into tb_app (id,name) values('0200002','TesT400001');
这里需要对 id 取前两位子字符串进行分片,即 00 分到节点 1,01 分到节点 2,依次类推。
这个分片规则默认没有写入规则配置,需要我们自行添加:
<tableRule name="sharding-by-substring">
<rule>
<columns>id</columns>
<algorithm>sharding-by-substring</algorithm>
</rule>
</tableRule>
<!-- 使用子字符串进行分片 -->
<function name="sharding-by-substring"
class="io.mycat.route.function.PartitionDirectBySubString">
<!-- 子字符串起始索引 -->
<property name="startIndex">0</property> <!-- zero-based -->
<!-- 子字符串长度 -->
<property name="size">2</property>
<!-- 分片(数据节点)个数 -->
<property name="partitionCount">3</property>
<!-- 默认分片 -->
<property name="defaultPartition">0</property>
</function>
添加使用该规则的逻辑表:
<table name="tb_app" dataNode="dn7,dn8,dn9" rule="sharding-by-substring"/>
重启 MyCat。
导入表结构和数据,可以看到数据按照前两位进行分片。因为我们配置了默认分片,所以这里如果前两位匹配不到分片,就会保存到默认分片。
固定分片 hash 算法
取用于分片的字段值的低10位,与 1111111111 进行位 & 运算。其计算结果在 0~1023 之间。我们可以将结果按照范围进行划分,存储到不同分片。
示例
添加分片规则:
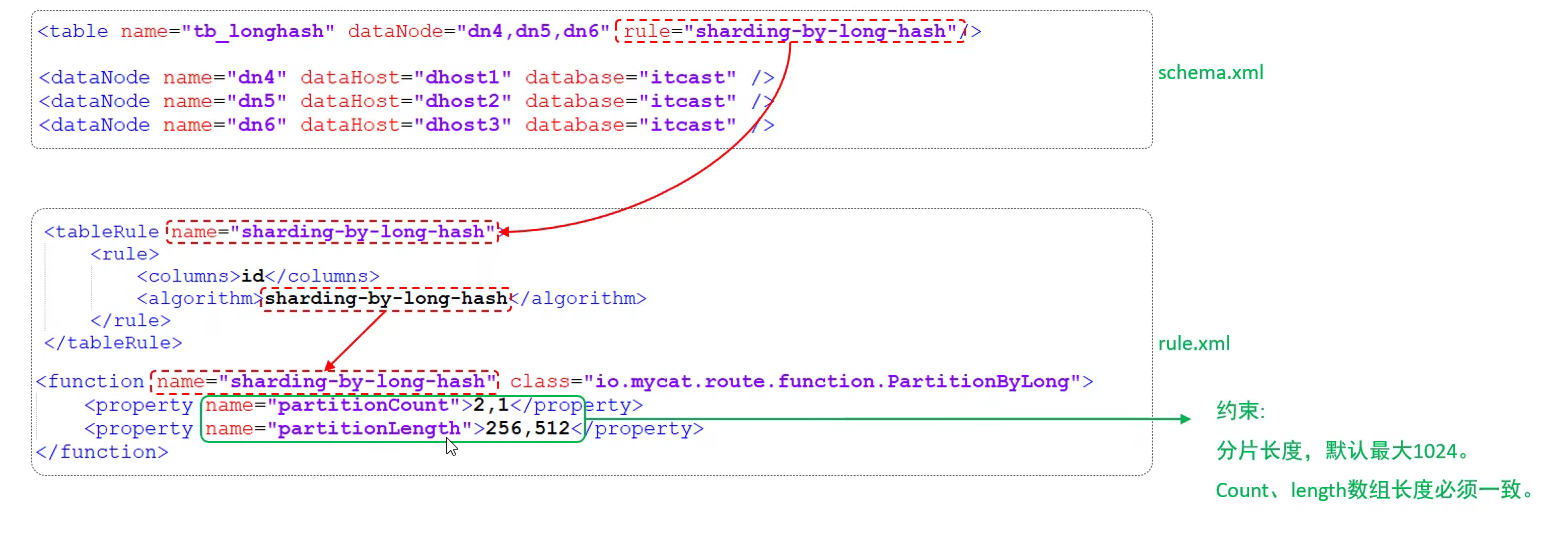
<tableRule name="sharding-by-long-hash">
<rule>
<columns>id</columns>
<algorithm>sharding-by-long-hash</algorithm>
</rule>
</tableRule>
<!-- 固定 hash 分片 -->
<function name="sharding-by-long-hash" class="io.mycat.route.function.PartitionByLong">
<!-- 分片数量,这里表示前2个容量为256,后1个容量为512 -->
<property name="partitionCount">2,1</property>
<!-- 分片容量划分,总和必须要为1024,这里是2*256+512=1024 -->
<property name="partitionLength">256,512</property>
</function>
固定 hash 分片的时候,数据节点存储的数据分布不一定要是均衡的,比如这里有3个分片,前两个分片长度都是 256,第三个分片长度是 512,意味着位与后的值,0~255 的保存在第一个分片,256~511 保存在第二个分片,512~1023 保存在第三个分片。
添加逻辑表:
<table name="tb_longhash" dataNode="dn7,dn8,dn9" rule="sharding-by-long-hash"/>
重启 MyCat,导入表结构和数据:
CREATE TABLE tb_longhash (
id int(11) NOT NULL COMMENT 'ID',
name varchar(200) DEFAULT NULL COMMENT '名称',
firstChar char(1) COMMENT '首字母',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into tb_longhash (id,name,firstChar) values(1,'七匹狼','Q');
insert into tb_longhash (id,name,firstChar) values(2,'八匹狼','B');
insert into tb_longhash (id,name,firstChar) values(3,'九匹狼','J');
insert into tb_longhash (id,name,firstChar) values(4,'十匹狼','S');
insert into tb_longhash (id,name,firstChar) values(5,'六匹狼','L');
insert into tb_longhash (id,name,firstChar) values(6,'五匹狼','W');
insert into tb_longhash (id,name,firstChar) values(7,'四匹狼','S');
insert into tb_longhash (id,name,firstChar) values(8,'三匹狼','S');
insert into tb_longhash (id,name,firstChar) values(9,'两匹狼','L');
insert into tb_longhash (id,name,firstChar) values(255,'两匹狼','L');
insert into tb_longhash (id,name,firstChar) values(256,'两匹狼','L');
insert into tb_longhash (id,name,firstChar) values(511,'两匹狼','L');
insert into tb_longhash (id,name,firstChar) values(512,'两匹狼','L');
insert into tb_longhash (id,name,firstChar) values(1023,'两匹狼','L');
insert into tb_longhash (id,name,firstChar) values(1024,'两匹狼','L');
字符串 hash 解析
截取指定字段的子字符串,再进行 hash,将 hash 值与 1023(1111111111)进行位与,作为分片依据。
示例
添加规则配置:
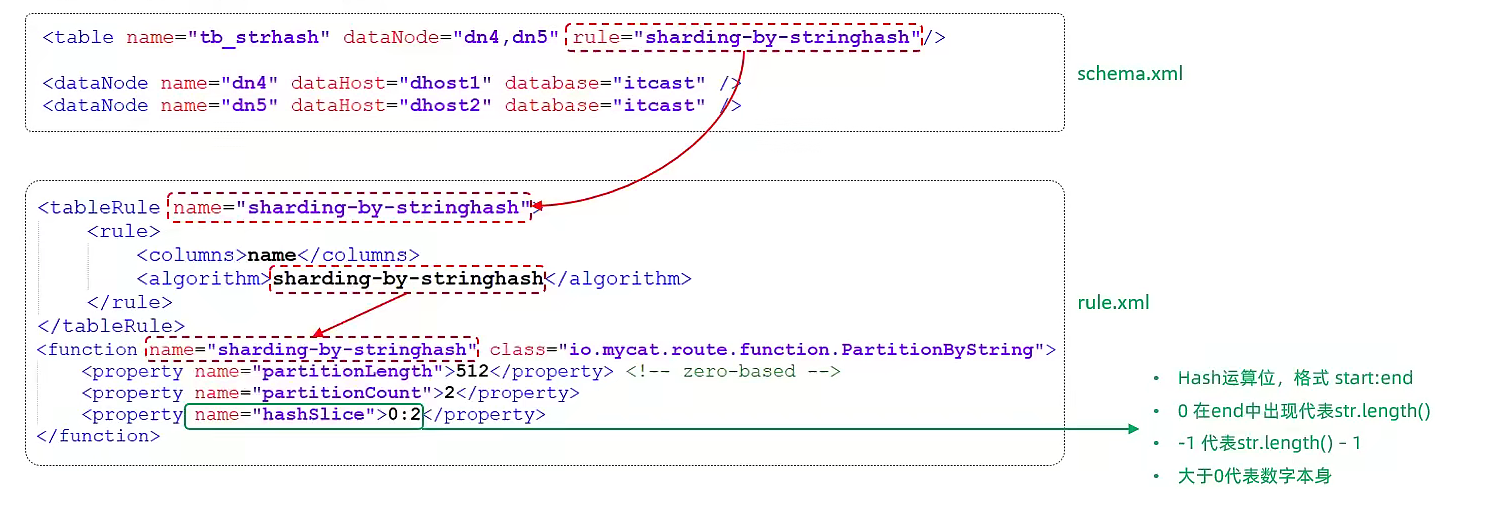
<tableRule name="sharding-by-stringhash">
<rule>
<columns>name</columns>
<algorithm>sharding-by-stringhash</algorithm>
</rule>
</tableRule>
<!-- 子字符串 hash 算法 -->
<function name="sharding-by-stringhash" class="io.mycat.route.function.PartitionByString">
<!-- 分片长度,这里两个分片长度相同,都是 512 -->
<property name="partitionLength">512</property> <!-- zero-based -->
<!-- 分片数量 -->
<property name="partitionCount">2</property>
<!-- 截取的子字符串,这里是截取索引为 0~2,长度为3的子字符串 -->
<property name="hashSlice">0:2</property>
</function>
添加逻辑表:
<table name="tb_strhash" dataNode="dn7,dn8" rule="sharding-by-stringhash"/>
重启 MyCat 后导入表结构和数据:
create table tb_strhash(
name varchar(20) primary key,
content varchar(100)
)engine=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO tb_strhash (name,content) VALUES('T1001', UUID());
INSERT INTO tb_strhash (name,content) VALUES('ROSE', UUID());
INSERT INTO tb_strhash (name,content) VALUES('JERRY', UUID());
INSERT INTO tb_strhash (name,content) VALUES('CRISTINA', UUID());
INSERT INTO tb_strhash (name,content) VALUES('TOMCAT', UUID());
按天分片
按天(日期)进行分片。
示例
创建分片规则:
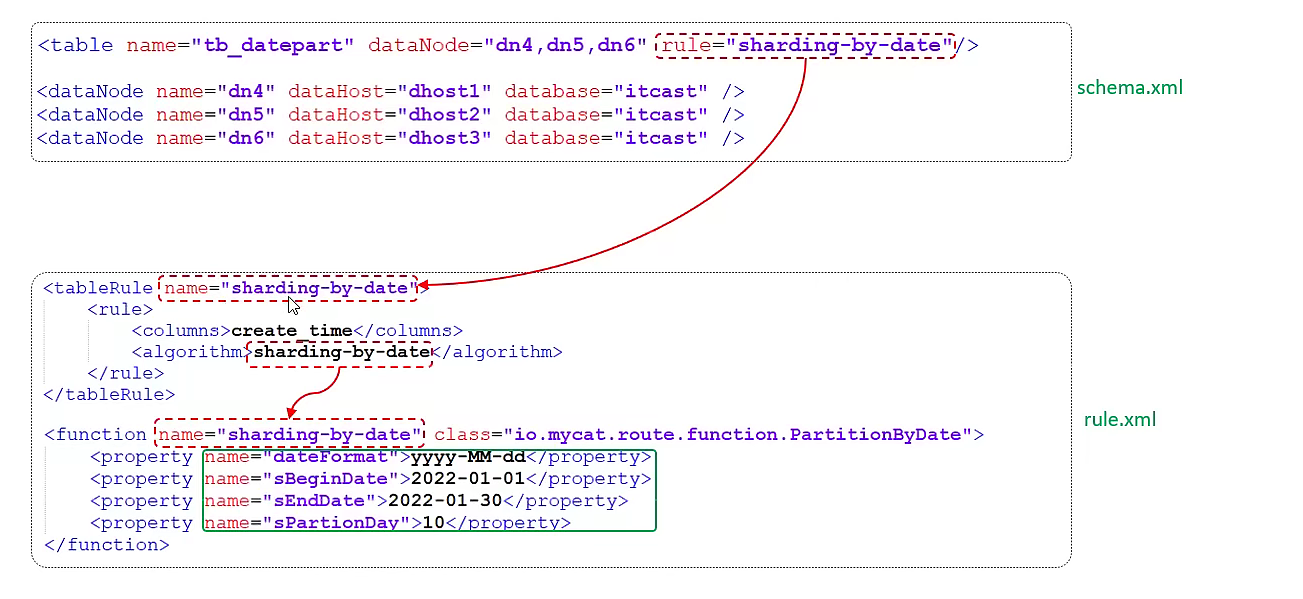
<tableRule name="my-sharding-by-date">
<rule>
<columns>create_time</columns>
<algorithm>my-sharding-by-date</algorithm>
</rule>
</tableRule>
<!-- 按日期进行分片 -->
<function name="my-sharding-by-date" class="io.mycat.route.function.PartitionByDate">
<!-- 日期格式-->
<property name="dateFormat">yyyy-MM-dd</property>
<!-- 开始日期 -->
<property name="sBeginDate">2022-01-01</property>
<!-- 结束日期,超过结束日期的,重新开始计算分片 -->
<property name="sEndDate">2022-01-30</property>
<!-- 每次分片的间隔天数 -->
<property name="sPartionDay">10</property>
</function>
在这种规则下,2022-01-01~2022-01-10 会分在第一个分片,2022-01-11~2022-01-20 会分在第二个分片,2022-01-21~2022-01-30 会分到第三个分片,超过结束日期的,比如 2022-01-31 会被重新从头分片,即分到第一个分片。
需要注意的是,这里通过设置计算出的分片个数(这里是3)需要与逻辑表配置的数据节点数目一致,否则会报错。
添加逻辑表:
<table name="tb_datepart" dataNode="dn7,dn8,dn9" rule="my-sharding-by-date"/>
自然月
示例
添加规则:
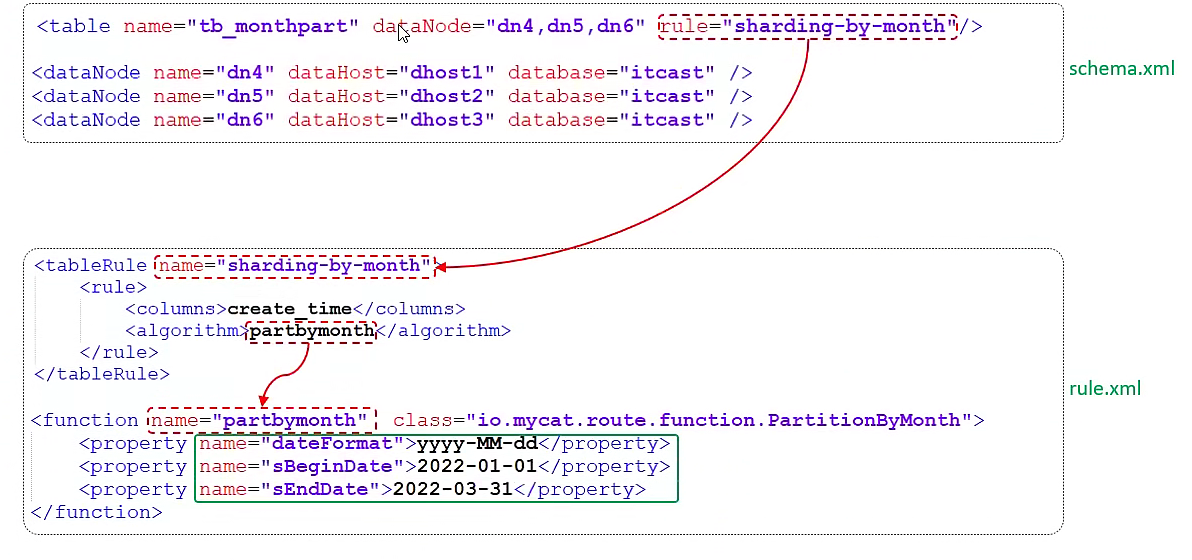
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<!-- 从开始时间到结束时间,每个自然月一个分片 -->
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2022-01-01</property>
<property name="sEndDate">2022-03-31</property>
</function>
这个规则 MyCat 的规则配置中已经存在,只需要按需求修改即可。
添加逻辑表:
<table name="tb_monthpart" dataNode="dn7,dn8,dn9" rule="sharding-by-month"/>
注意,这里逻辑表的分片数(数据节点个数)要与分片算法(function)中计算出的分片数一致,否则会报错。
重启 MyCat 后导入数据:
create table tb_monthpart(
id bigint not null comment 'ID' primary key,
name varchar(100) null comment '姓名',
create_time date null
);
insert into tb_monthpart(id,name ,create_time) values(1,'Tom','2022-01-01');
insert into tb_monthpart(id,name ,create_time) values(2,'Cat','2022-01-10');
insert into tb_monthpart(id,name ,create_time) values(3,'Rose','2022-01-31');
insert into tb_monthpart(id,name ,create_time) values(4,'Coco','2022-02-20');
insert into tb_monthpart(id,name ,create_time) values(5,'Rose2','2022-02-25');
insert into tb_monthpart(id,name ,create_time) values(6,'Coco2','2022-03-10');
insert into tb_monthpart(id,name ,create_time) values(7,'Coco3','2022-03-31');
insert into tb_monthpart(id,name ,create_time) values(8,'Coco4','2022-04-10');
insert into tb_monthpart(id,name ,create_time) values(9,'Coco5','2022-04-30');
管理与监控
原理
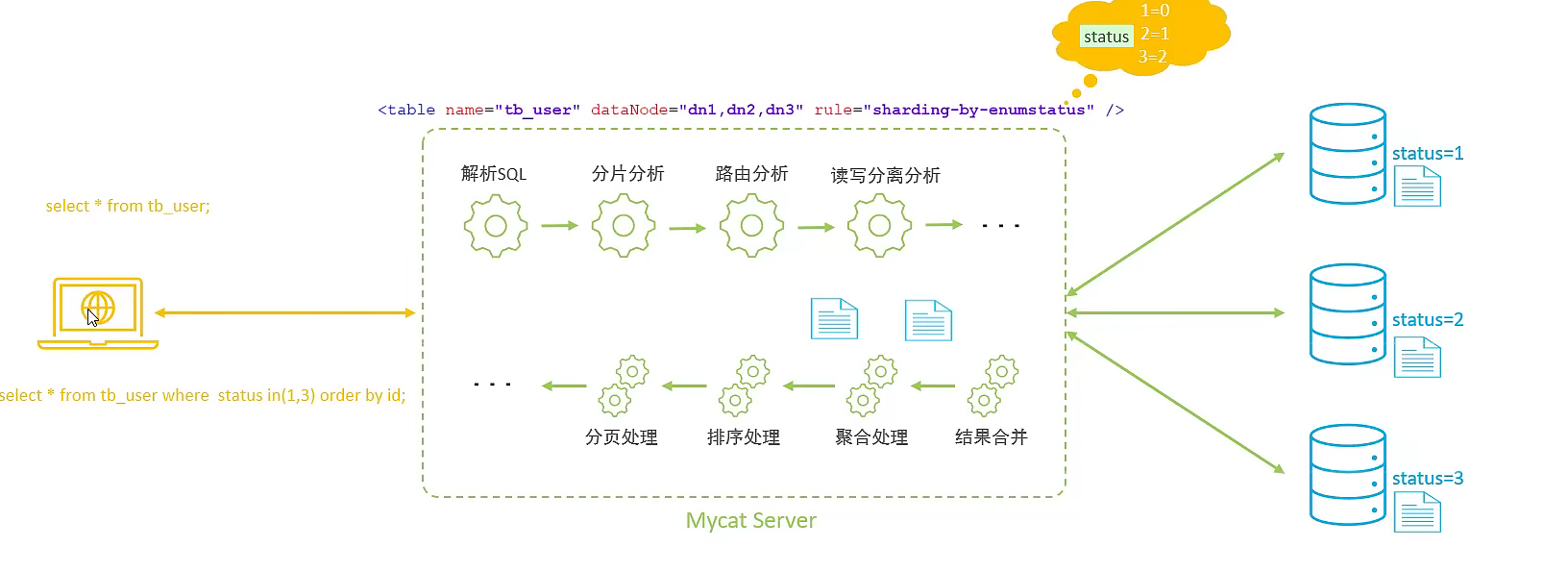
关于 MyCat 执行 SQL 原理的说明,可以观看视频。
管理工具
可以通过以下命令连接到 MyCat 的管理工具:
mysql -h192.168.0.88 -P9066 -uroot -p
管理工具默认端口是 9066
常用命令有:
| 命令 | 含义 |
|---|---|
| show @@help | 查看 MyCat 管理工具帮助文档 |
| show @@version | 查看 MyCat 的版本 |
| reload @@config | 重新加载 MyCat 的配置文件 |
| show @@datasource | 查看 MyCat 的数据源信息 |
| show @@datanode | 查看 MyCat 现有分片节点信息 |
| show @@threadpool | 查看 MyCat 的线程池信息 |
| show @@sql | 查看执行的 SQL |
| show @@sql.sum | 查看执行的 SQL 统计 |
命令的使用演示可以观看视频。
监控
Mycat-web(Mycat-eye) 是对mycat-server提供监控服务,功能不局限于对 mycat-server使用。他通过JDBC连接对 Mycat、Mysql 监控,监控远程服务器(目前仅限于 linux 系统)的cpu、内存、网络、磁盘。
Mycat-eye运行过程中需要依赖 zookeeper,因此需要先。
安装好 Zookeeper 后再。
MyCatEye 的使用可以观看视频。
似乎 MyCatEye 会很消耗 MyCat 的性能,在我的测试机(虚拟机)上,同时开启 MyCatEye 和 MyCat,会导致 MyCat 上的 SQL 查询长时间没响应甚至断开连接。关闭 MyCatEye 后恢复正常。


文章评论