
图源:
之前用两篇文章介绍了 JPA 中的和,实际上日常开发更多见的是多对多关系,本文将介绍如何在 JPA 中实现实体的多对多关系。
可以用数据模型表示为:
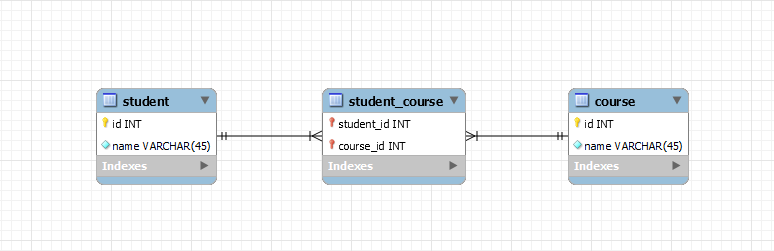
我们用一个中间表(关联表)保存两个表之间的这种多对多的关联关系。
这里有一个细节,两个表与关联表之间的关系是一对多的。这很好理解,一个学生可以在关联表中出现多次。同样的,一门课程,也可以在关联表中出现多次。
@JoinTable
这用 JPA 实体可以表示为:
// ...
(name = "student")
public class Student {
// ...
(cascade = {CascadeType.PERSIST, CascadeType.MERGE})
(c = "student_course",
joinColumns = {(name = "student_id")},
inverseJoinColumns = {(name = "course_id")})
private List<Course> courses = new ArrayList<>();
// ...
}
// ...
(name = "course")
public class Course {
// ...
(mappedBy = "courses")
private List<Student> students = new ArrayList<>();
}
这里并没有为关联表创建实体,而是用@JoinTable的方式在Student中体现关联关系。
@JoinTable有以下属性需要设置:
-
name,关联表的名称。 -
joinColumns,当前表与关联表的外键约束。 -
inverseJoinColumns,另一端的表与关联表的外键约束。
这些属性都是可选的,如果缺省,Hibernate 会为我们自动生成。但为了数据库表结构的可读性,最好还是自己设定。
此外,@ManyToMany并没有一个类似于@ManyToOne的orphanRemoval属性,这是因为在多对多的情况下,级联删除往往是行不通的。因为即使我们要删除一些学生,也不能将其关联的课程也全部删除,因为这些课程很可能有其它学生关联。
最后,与一对多和多对多关系还不同的一点是,两个多对多关联的表,它们的关系是平等的。事实上它们之间的关联关系也由中间表(关联表)来保存和体现。因此,并没有绝对意义上的“关系的拥有者”,但 Hibernate 的语法要求我们必须指定一个,因此我们随意选择一方作为“关系的拥有者”即可。在这个示例中我指定了Student,但实际上使用Course作为“关系的拥有者”也是完全可行的。
最终,Hibernate 会根据实体生成如下的 DDL:
CREATE TABLE `student` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(45) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
CREATE TABLE `course` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(45) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
CREATE TABLE `student_course` (
`student_id` bigint NOT NULL,
`course_id` bigint NOT NULL,
KEY `FKejrkh4gv8iqgmspsanaji90ws` (`course_id`),
KEY `FKq7yw2wg9wlt2cnj480hcdn6dq` (`student_id`),
CONSTRAINT `FKejrkh4gv8iqgmspsanaji90ws` FOREIGN KEY (`course_id`) REFERENCES `course` (`id`),
CONSTRAINT `FKq7yw2wg9wlt2cnj480hcdn6dq` FOREIGN KEY (`student_id`) REFERENCES `student` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
在这种构建实体的方式下,如果我们从一个实体中删除对另一个实体的关联,仅仅会删除关系表中的数据:
var course = student.getCourses().get(0);
student.getCourses().remove(course);
studentRepository.save(student);
如果查看 Hibernate 日志,就能看到类似下面的记录:
delete from student_course where student_id=4 insert into student_course (student_id,course_id) values (4,6) insert into student_course (student_id,course_id) values (4,7)
原始的数据是学生4绑定了课程5、课程6、课程7。
看上去很奇怪,本来应该只有一条 DELETE SQL,但实际上是先删除了所有有关学生4的关联关系,再将不用删除的数据添加回去。这是因为缺乏关联表实体导致的,如果有关联表实体就不会出现这个问题(稍后会看到)。
关联表实体
大多数情况可以像上面那样,无需为关联表创建实体,但有时候我们不得不为关联表创建实体。
假设我们需要让学生可以对选择的课程打分,很显然,从数据库设计的角度,应该添加一个字段到关联表。自然的,在 JPA 中也就要为关联表创建实体。
// ...
(name = "Student2")
(name = "student2")
public class Student {
// ...
(mappedBy = "student",
cascade = CascadeType.ALL,
orphanRemoval = true)
private List<StudentCourse> studentCourses = new ArrayList<>();
// ...
}
// ...
(name = "Course2")
(name = "course2")
public class Course {
// ...
(mappedBy = "course",
cascade = CascadeType.ALL,
orphanRemoval = true)
private List<StudentCourse> studentCourses = new ArrayList<>();
// ...
}
// ...
(name = "StudentCourse2")
(name = "student_course2")
public class StudentCourse {
public static class StudentCourseId implements Serializable {
private Long studentId;
private Long courseId;
}
.Exclude
private StudentCourseId id = new StudentCourseId();
(0)
(100)
private Integer rate;
(name = "student_id")
("studentId")
private Student student;
(name = "course_id")
("courseId")
private Course course;
}
实际上这种关联关系已经变成了两组一对多的关联关系。这是符合关系型数据库的设计思路的,因为在关系型数据库设计中,实际上是不存在多对多关系的,多对多关系都会表示为两组一对多关系。
Hibernate 生成的 DDL:
CREATE TABLE `student2` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(45) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=55 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
CREATE TABLE `course2` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(45) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=73 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
CREATE TABLE `student_course2` (
`course_id` bigint NOT NULL,
`student_id` bigint NOT NULL,
`rate` int NOT NULL,
PRIMARY KEY (`course_id`,`student_id`),
KEY `FK1g5h5g8jo3xx52yls752d0u5v` (`student_id`),
CONSTRAINT `FK1g5h5g8jo3xx52yls752d0u5v` FOREIGN KEY (`student_id`) REFERENCES `student2` (`id`),
CONSTRAINT `FKbfdrjjuchuco4u8fwgvmvsv3t` FOREIGN KEY (`course_id`) REFERENCES `course2` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
在处理这种实体建模时,需要先添加基本实体(不带关系的),让这些基本实体变成持久状态(保存到数据库)后,才能添加实体之间的关联关系,比如:
// ...
studentRepository.saveAll(students);
courseRepository.saveAll(courses);
TestTransaction.flagForCommit();
TestTransaction.end();
TestTransaction.start();
student1.addCourse(math, 99);
student1.addCourse(physics, 90);
student1.addCourse(chemistry, 88);
student2.addCourse(art, 100);
student2.addCourse(math, 90);
student3.addCourse(chemistry, 90);
student3.addCourse(art, 95);
studentRepository.saveAll(students);
// ...
否则就可能因为 Hibernate 对关联表实体持久化时对同一个对象分配不同的Id。错误信息如下:
org.springframework.dao.DataIntegrityViolationException: A different object with the same identifier value was already associated with the session : [com.example.manytomany.v2.StudentCourse#com.example.manytomany.v2.StudentCourse$StudentCourseId@1cae]
此外,默认情况下一对多关系使用延迟加载,所以进行关联查询时需要将查询包含在一个事务中:
@Test
void test() {
if (!TestTransaction.isActive()){
TestTransaction.start();
TestTransaction.flagForCommit();
}
var students = studentRepository.findAll();
students.forEach(s -> {
System.out.println("Student: " + s.getName());
var studentCourses = s.getStudentCourses();
studentCourses.forEach(sc -> {
var cName = sc.getCourse().getName();
System.out.println("Course: %s, Rate: %d".formatted(cName, sc.getRate()));
});
});
TestTransaction.end();
}
如果不这么做,代理对象就无法正常工作。
和之前不同的是,现在这种方式下删除关联关系的效率会更好,比如:
icexmoon.removeCourse(course);
entityManager.persist(icexmoon);
entityManager.flush();
Hibernate 的 SQL 日志如下:
delete from student_course2 where course_id=129 and student_id=97
准确地删除了一条关联关系数据,并不像之前那样先全部删除再重新添加。
总结
一般来说,我们用第一种方式即可,不用为中间实体建模会让关系复杂度降低。但如果需要中间实体保存某些信息,我们就不得不为中间实体建模。
The End,谢谢阅读。
本文的完整示例可以从获取。


文章评论