
图源:
之前在中介绍了MyBatis Plus的基本用法,这里再介绍一些那篇文章没有介绍的内容。
本篇的示例代码将会基于的最终代码修改而来,对应的完整代码见。
分页
在开发系统时最常见的需求之一就是对数据进行分页查询,使用MyBatis Plus可以很容易地实现分页查询。
在介绍参数校验的时候(),我为books应用添加了一个处理分页查询请求的方法getPagedBooks,但实际上并没有实现其数据库查询逻辑,我们看如何实现。
现在IBookService中添加一个用于分页查询的方法:
public interface IBookService extends IService<Book> {
IPage<Book> getPagedBooks(IPage<Book> page);
}
在BookServiceImpl中实现该方法:
public class BookServiceImpl extends ServiceImpl<BookMapper, Book> implements IBookService {
public IPage<Book> getPagedBooks(IPage<Book> page) {
return this.page(page);
}
}
这里的IPage是一个MyBatis Plus定义的分页用的接口,通过该接口可以获取分页查询和返回所需的所有内容。
默认情况下MBP的分页是不生效的,为了让其生效,我们要添加MBP配置:
public class MybatisPlusConfig {
// 最新版
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
再添加一个包含返回分页信息的实体类:
public class PageResponse {
("总页数")
private Long total;
("当前页数")
private Long current;
("用于分页的数据行数")
private Long paging;
("总数据条数")
private Long totalRecords;
}
然后就可以在控制器层添加分页查询和返回数据的代码了:
...
private static class GetPagedBooksDTO {
private PageRequest pageRequest;
}
private static class GetPagedBooksVO {
("书籍列表")
private List<Book> books;
("分页信息")
private PageResponse pageResponse;
}
("/book/page")
("获取分页的书籍列表")
public GetPagedBooksVO getPagedBooks( GetPagedBooksDTO dto) {
log.info("current:" + dto.getPageRequest().getCurrent());
log.info("paging:" + dto.getPageRequest().getPaging());
PageRequest pageRequest = dto.getPageRequest();
IPage<Book> pagedBooks = bookService.getPagedBooks(new Page<>(pageRequest.getCurrent(), pageRequest.getPaging()));
GetPagedBooksVO vo = new GetPagedBooksVO();
vo.setBooks(pagedBooks.getRecords());
PageResponse pageResponse = new PageResponse();
pageResponse.setPaging(pagedBooks.getSize());
pageResponse.setCurrent(pagedBooks.getCurrent());
pageResponse.setTotal(pagedBooks.getTotal() / pagedBooks.getSize() + 1);
pageResponse.setTotalRecords(pagedBooks.getTotal());
vo.setPageResponse(pageResponse);
return vo;
}
...
现在查询就能正确获取到分页后的数据了。
我们还可以重构上边的代码,通过让自定义的PageRequest和PageResponse支持转换为IPage以及从IPage转换,就会让代码变得更加简洁:
public class PageRequest {
("当前页码")
(1)
private Integer current;
("每页分页数据条数")
(1)
private Integer paging;
/**
* 返回PageRequest对应的Page对象
*
* @param <T>
* @return
*/
public <T> Page<T> getPage() {
Page<T> page = new Page<>();
page.setCurrent(current);
page.setSize(paging);
return page;
}
}
public class PageResponse {
("总页数")
private Long total;
("当前页数")
private Long current;
("用于分页的数据行数")
private Long paging;
("总数据条数")
private Long totalRecords;
/**
* 根据IPage获取PageResponse
*
* @param ipage
* @return
*/
public static PageResponse getPageResponse(IPage ipage) {
PageResponse pageResponse = new PageResponse();
pageResponse.setTotal(ipage.getPages());
pageResponse.setCurrent(ipage.getCurrent());
pageResponse.setPaging(ipage.getSize());
pageResponse.setTotalRecords(ipage.getTotal());
return pageResponse;
}
}
("/book/page")
("获取分页的书籍列表")
public GetPagedBooksVO getPagedBooks( GetPagedBooksDTO dto) {
log.info("current:" + dto.getPageRequest().getCurrent());
log.info("paging:" + dto.getPageRequest().getPaging());
IPage<Book> pagedBooks = bookService.getPagedBooks(dto.getPageRequest().getPage());
GetPagedBooksVO vo = new GetPagedBooksVO();
vo.setBooks(pagedBooks.getRecords());
vo.setPageResponse(PageResponse.getPageResponse(pagedBooks));
return vo;
}
可能有人会为了减少代码,采取不使用自定义的分页实体来传入和返回分页信息,而是直接使用IPage等MyBatis Plus的官方类。但我觉得这样有两个缺陷:
-
MyBatis Plus的
IPage接口中有很多不必要的信息,比如请求时所需传递的分页信息只应当有当前页码和每页数据条数。 -
让控制器层和数据库的分页紧耦合,很难扩展。比如在我的一个项目中,需要调用第三方系统的接口,那个系统的分页相关的接口页码都是从0开始,而不是MyBatis Plus的从1开始,而我只需要修改
PageRequest和PageResponse,就可以很容易地兼容这种情况,对于我的前端来说,所有页码都是从1开始。
枚举
我们可以很容易地利用MyBatis Plus在数据库层实体(DAO)中使用枚举,这点我在中介绍过了,这里不重复说明。
软删除
我参加工作以来,参与开发的所有系统几乎都是使用软删除,虽然有DBA定期备份的正式系统而言,数据找回不是什么做不到的事,但是有软删除存在有时候真的会少不少麻烦。
以前做PHP开发的时候,大多时间都是在相应的表创建del_flag字段,然后自己写SQL实现软删除,当然也不乏在测试阶段发现某个bug是因为在查询时没有使用del_flag字段造成的。
使用MyBatis Plus可以很轻松地实现对软删除的支持,你甚至不需要在使用其API时做任何修改。
首先我们要给系统中的所有表接口都增加一个del_flag字段作为软删除的标识。
需要注意的是,最好为
del_flag添加上默认值0。
还需要在所有的数据库层实体添加delFlag,这里以Book类为例:
(callSuper = false)
("book")
public class Book implements Serializable {
...
private Integer delFlag;
}
必须为所有的DAO类都添加,如果漏加,相应的数据库实体执行删除操作就会执行硬删除。
在控制器中添加一个方法用于删除书籍:
("/book/del/{id}")
public Result delBook(("书籍id") Integer id) {
bookService.removeById(id);
return Result.success();
}
这里的
IService.removeById方法是MyBatis Plus定义的,一般删除不会有复杂的业务逻辑,这里直接使用。
如果测试就会发现,通过该接口删除书籍后,数据库中实际上是将相应的书籍条目的del_flag字段修改为1,也就是所谓的用UPDATE代替DELETE完成删除逻辑。
JSON字段
如果我们要存储的图书需要添加一个新的属性,比如出版社,给book表增加一个新字段是最容易想到的。但这样做有连个缺点:
-
可能导致表的字段数急剧增加。
-
比较麻烦,每次都需要修改表结构和在相应DAO类中增加属性。
除了这种方式外,我们还可以考虑增加一个通用字段,用于存储格式化的字符串。
当然,目前绝大多数格式化字符串实际上指的就是JSON,XML和其它序列化方式相比JSON,要么可读性不佳,要么需要更多的存储空间。
这里以添加一个JSON化的通用存储字段为例进行说明。
首先为book表增加一个extra字段用于存放JSON后的数据:
CREATE TABLE `book` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(45) NOT NULL,
`description` text NOT NULL,
`user_id` int NOT NULL,
`type` tinyint NOT NULL DEFAULT '5' COMMENT '书籍类型 1艺术 2小说 3科幻 4历史 5其它',
`extra` text NOT NULL,
`del_flag` tinyint NOT NULL DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=18 DEFAULT CHARSET=utf8mb3
这里
extra使用了TEXT类型,是考虑了未来可能的扩展性,如果存储的内容有限,可以使用VARCHAR类型。
然后在DAO中添加对应的属性:
(callSuper = false)
("book")
public class Book implements Serializable {
public static class Extra {
private String Publisher;
private String ISBN;
}
private static final long serialVersionUID = 1L;
(value = "id", type = IdType.AUTO)
private Integer id;
private String name;
private String description;
private Integer userId;
private BookType type;
private Extra extra;
private Integer delFlag;
}
JSON字段的类型定义为内部类Extra,这样做可以让其从属关系更加明显。
显然,MBP并不会“自动”完成Extra到JSON的转换或者相反的转换,为了让MBP知道怎么做,我们需要创建一个类型处理器(TypeHandler):
(callSuper = false)
("book")
public class Book implements Serializable {
public static class Extra implements Serializable {
public static class ExtraTypeHandler extends AbstractJsonTypeHandler<Extra> {
public ExtraTypeHandler() {
super();
}
protected Extra parse(String json) {
return JSON.parseObject(json, Extra.class);
}
protected String toJson(Extra obj) {
return JSON.toJSONString(obj);
}
}
public static Extra newInstance(String ISBN, String publisher) {
Extra extra = new Extra();
extra.setISBN(ISBN);
extra.setPublisher(publisher);
return extra;
}
...
}
...
}
要创建一个TypeHandler,最简单的方式是继承抽象类AbstractJsonTypeHandler,当然你也可以选择自己实现TypeHandler接口,但一般来说是不必要的。
此外需要注意的是,要为ExtraTypeHandler定义一个public的构造器,否则就会因为MBP无法创建TypeHandler而报错。
下面我们修改控制器层,让添加书籍接口能够在添加书籍时附带上ISBN和出版社信息:
private static class AddBookDTO {
...
("ISBN")
private String isbn;
("出版社")
private String publisher;
}
("manager")
("/book/add")
("添加书籍")
public Result addBook( AddBookDTO dto) {
...
book.setExtra(Book.Extra.newInstance(dto.getIsbn(), dto.getPublisher()));
bookService.save(book);
return Result.success();
}
就像展示的那样,只需要修改少量代码就可以实现。
现在你可以试着调用这个接口添加书籍了,其中isbn和publisher是可选参数,如果请求包含这两个参数,数据库中产生的新的book数据的extra字段就会有相应的内容,比如像这样:
{"iSBN":"111-222","publisher":"海南出版社"}
奇怪的是DTO中的属性必须被定义为小写,如果定义了
AddBookDTO.ISBN这样的属性,框架就无法正常绑定数据。
我们同样可以试着修改获取书籍详情的接口,让书籍详情接口返回ISBN和出版社信息:
private static class GetBookInfoVO implements IResult {
...
private String isbn;
("出版社")
private String Publisher;
public static GetBookInfoVO newInstance(Book book) {
...
Book.Extra extra = book.getExtra();
if (extra != null) {
vo.setIsbn(extra.getISBN());
vo.setPublisher(extra.getPublisher());
}
return vo;
}
}
遗憾的是如果你测试就会发现返回的ISBN和出版社信息都是null。
要能正常返回JSON字段的信息也很容易,修改DAO类的@TableName注解,将其属性autoResultMap设置为true即可:
(value = "book", autoResultMap = true)
public class Book implements Serializable {
...
}
再尝试就能看到正确加载JSON格式的信息并返回了:
{
"success": true,
"msg": "",
"data": {
"id": 25,
"name": "自由与和平",
"desc": "自由与和平",
"uid": 1,
"bookType": 1,
"isbn": "111-222",
"publisher": "海南出版社"
},
"code": 200
}
同样的,我们可以通过重构让添加JSON字段变得更容易。
首先,为了复用JSON和反JSON部分代码,我们在AbstractJsonTypeHandler基础上扩展一个MyJsonTypeHandler类,这个类同样是一个泛型类,可以将任意类型进行JSON和反JSON。
public class MyJsonTypeHandler<T> extends AbstractJsonTypeHandler<T> {
private Class<T> cls;
public MyJsonTypeHandler(Class<T> cls) {
this.cls = cls;
}
protected T parse(String json) {
return JSON.parseObject(json, cls);
}
protected String toJson(T obj) {
return JSON.toJSONString(obj);
}
}
需要注意的是,因为对JSON字符串进行解析时,解析器是需要提供Class对象作为类型依据的,所以这里必须让MyJsonTypeHandler通过构造器持有一个Class<T>类型的句柄。
有了MyJsonTypeHandler我们就可以很容易地视线具体目标类型所需的TypeHandler类了:
(callSuper = false)
(value = "book", autoResultMap = true)
public class Book implements Serializable {
public static class Extra implements Serializable {
public static class ExtraTypeHandler extends MyJsonTypeHandler<Extra> {
public ExtraTypeHandler() {
super(Extra.class);
}
}
...
}
...
}
因为ExtraTypeHandler继承自我们新定义的MyJsonTypeHandler类,所以不需要再实现JSON和反JSON的相应方法了,只需要重写构造器,在默认构造器中提供一个Class对象给父类构造器即可。
联表查询
虽然说大多数情况下执行的SQL都是针对单表的,但是无法避免地,有时候我们需要联表查询。
比如说在我们的表结构中:
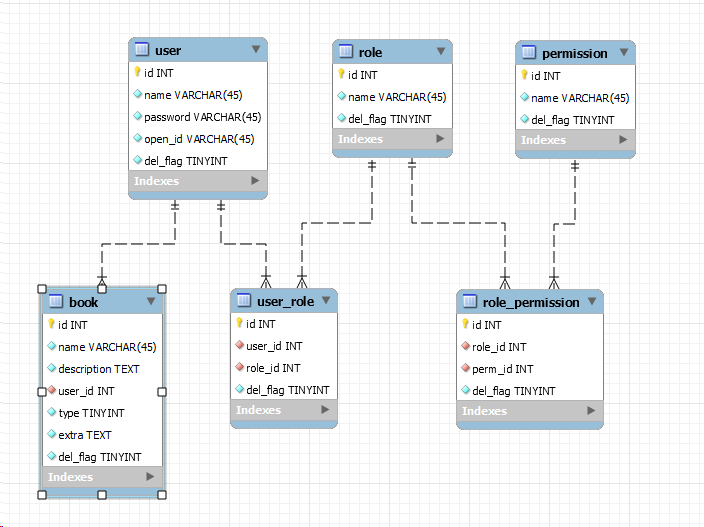
book和user用user_id字段进行关联,表示书籍的添加人,如果我们要在分页查询时显示添加人的姓名,要怎么做?
大概新手会采用先查询book,获取到结果后再通过遍历的方式逐条查询user最终拼凑出所需的数据。
这样做的缺点是:
-
SQL执行效率低,假设每页有10条数据,那这样就需要11次SQL查询才能获取结果。如果采用联表查询,只需要一次SQL。即使联表查询效率低于单表查询,但单次SQL执行的开销也会让前者显著要慢于后者。
-
让Service层代码复杂度上升,用联表SQL很容易表达的查询逻辑,被迭代和单条数据查询等代码代替。
-
无法实现一些复杂查询逻辑,比如说查询添加人姓名是某个字开头的用户添加的书籍等。
其实也可以通过Redis等缓存技术改善上面所说的查询效率问题,这里不做讨论。
下面我们看如何实现联表查询。
Spring中联表查询的SQL需要编写在Mapper相关的XML文件中,在我们这个示例项目中,resource目录下已经按模块创建好XML文件了,所以这里只需要填充BookMapper.xml即可:
<mapper namespace="cn.icexmoon.demo.books.book.mapper.BookMapper">
<select id="getPagedBooks" resultType="Book">
SELECT b.*, u.`name` AS uname
FROM book AS b
LEFT JOIN `user` AS u
ON b.`user_id` = u.`id`
WHERE b.`del_flag` = 0
AND u.`del_flag` = 0
</select>
</mapper>
需要注意的是,通过这种方式实现的SQL查询,MBP不会自动添加上软删除的相关查询条件,所以我们要在SQL中加上del_flag的相关查询条件。此外,SQL结尾不能添加SQL结束符号;,因为MBP会按需要给SQL结尾追加特殊的SQL语句(比如LIMIT),如果这里添加了;就会在那种情况下导致SQL查询失败。
select标签的id属性对应的是对应Mapper接口中的方法名称,而resultType属性对应的是查询结果对应的DAO类。
给BookMapper接口添加对应方法:
public interface BookMapper extends BaseMapper<Book> {
/**
* 获取分页的书籍列表
*
* @param page
* @return
*/
IPage<Book> getPagedBooks(IPage<Book> page);
}
这里因为是分页查询,所以依然按照MBP的风格传入一个IPage参数并返回一个IPage类型结果。不过这些并不需要在XML中的SQL中体现,MBP会自动给SQL追加上LIMIT相关SQL语句。
修改Service,引入Mapper并通过Mapper查询书籍分页信息:
public class BookServiceImpl extends ServiceImpl<BookMapper, Book> implements IBookService {
private BookMapper bookMapper;
public IPage<Book> getPagedBooks(IPage<Book> page) {
return bookMapper.getPagedBooks(page);
}
}
现在编译项目并启动,可能会出现一个错误:“因为找不到Book类而产生的BookMapper.xml解析错误 ”。
这是因为默认情况下在Mapper中的select的resultType属性中需要指定完整包名,这样相应的解析器才能查找到类,如果像上面那样使用简写类名,就需要添加额外的MBP配置:
#联表查询时查找DAO类的包路径
mybatis-plus.type-aliases-package=cn.icexmoon.demo.books.*.entity
最后在Book实体中添加一个uname属性来保存联表查询到的用户名:
(callSuper = false)
(value = "book", autoResultMap = true)
(chain = true)
public class Book implements Serializable {
...
(exist = false)
private String uname;
}
因为uname是非单表查询的字段,所以需要添加上@TableField(exist = false)注解,否则会让相关单表查询API失败。
现在执行分页查询,就能看到带有用户姓名的分页信息:
{
"books": [
{
"id": 15,
"name": "自由与和平",
"description": "自由与和平",
"userId": 1,
"type": 5,
"extra": null,
"delFlag": 0,
"uname": "icexmoon"
}
],
"pageResponse": {
"total": 9,
"current": 5,
"paging": 3,
"totalRecords": 25
}
}
按照上面这种方式,如果我们还需要在书籍分页中显示用户的open_id,就需要给book再增加一个字段。这样显然是不优雅的,我们可以有更好的解决方案。
首先修改BookMapper.xml中的SQL查询,让其返回user表中的字段:
SELECT
b.*,
u.`name` AS uname,
u.`id` AS uid,
u.`open_id` AS uopen_id,
u.`password` AS upassword,
u.`del_flag` AS udel_flag
FROM
book AS b
LEFT JOIN `user` AS u
ON b.`user_id` = u.`id`
WHERE b.`del_flag` = 0
AND u.`del_flag` = 0
在BookMapper.xml的根节点mapper下添加一个子节点resultMap,用这个节点定义一个自定义的基于Book类的DAO到数据库映射:
<resultMap id="BookResultMap" type="Book">
<id column="id" property="id"/>
<result column="name" property="name"/>
<result column="description" property="description"/>
<result column="user_id" property="userId"/>
<result column="type" property="type"/>
<result column="extra" property="extra"
typeHandler="BookExtraTypeHandler"/>
<result column="del_flag" property="delFlag"/>
<association property="user" javaType="User">
<id column="uid" property="id"/>
<result column="uopen_id" property="openId"/>
<result column="upassword" property="password"/>
<result column="uname" property="name"/>
<result column="udel_flag" property="delFlag"/>
</association>
</resultMap>
resultMap节点的包含两个主要属性:
-
id,可以自定义,稍后将会用这个id将包含SQL查询的select节点与resultMap关联起来。 -
type,类似于之前select节点中的resultType属性,需要指定一个DAO类,作为从数据库中查询数据后绑定的实体对象。
resultMap节点包含三种主要的子节点:
-
id,指定查询结果中主表的主键与当前DAO实体的绑定关系。 -
column,指定查询结果中主表其它字段(非主键)与当前DAO实体的绑定关系。 -
association,使用当前DAO实体的一个字段建立与关联表的数据绑定关系。
这里所谓的主表和关联表以及绑定关系只是从习惯性的角度出发描述,实际上这种绑定关系完全是由你通过XML描述确定的,所以你可以按自己的需要任意建立对应关系,只不过一般情况下都是按照主表和副表这样的形式组织。
id和column都有相同的属性:
-
column,指定SQL查询结果中的字段名 -
property,指定DAO类中的属性名称 -
typeHandler,如果要绑定的属性是一个非包装器类/枚举类型,就需要指定一个前面介绍过的类型处理器,需要通过这个属性指定一个类作为类型处理器。 -
javaType,DAO类中属性的Java类型,一般无需指定,使用默认值即可。 -
jdbcType,查询结果中的字段的数据库类型,一般无需指定,使用默认值即可。
这里需要注意的是,typeHandler属性值中的类型处理器不能是内部类,比如typeHandler="Book.Extra.BookExtraTypeHandler",这样做会导致一个“无法找到类Book.Extra.BookExtraTypeHandler"的错误。
目前不清楚这是一个MBP的bug还是特性,为此我们不得不单独创建一个类来定义类型处理器:
public class BookExtraTypeHandler extends MyJsonTypeHandler<Book.Extra> {
public BookExtraTypeHandler() {
super(Book.Extra.class);
}
}
为了避免代码重复,重构Book类,使用这个新定义的类型处理器取代内部类。
(callSuper = false)
(value = "book", autoResultMap = true)
(chain = true)
public class Book implements Serializable {
public static class Extra implements Serializable {
public static Extra newInstance(String ISBN, String publisher) {
Extra extra = new Extra();
extra.setISBN(ISBN);
extra.setPublisher(publisher);
return extra;
}
private String Publisher;
private String ISBN;
}
...
(typeHandler = BookExtraTypeHandler.class)
private Extra extra;
...
}
让我们回到BookMapper.xml,association节点包含两个属性:
-
property,当前DAO对象中用于关联副表查询结果的“关联对象”所在的属性名。 -
javaType,该属性的Java类型。
association的结构与resultMap类似,同样可以包含id、result子节点。通过这些节点可以创建SQL查询结果中关联表中的字段与关联对象的对应关系。
最后,需要修改select节点,将resultType属性修改为resultMap属性,并通过该属性关联自定义的resultMap:
<select id="getPagedBooks" resultMap="BookResultMap">
因为
resultType和resultMap这两个属性名过于相似,一开始我忽略了这点,所以一直报“找不到类BookResultMap”的错误,这是因为解析器试图按照resultType那样将BookResultMap作为一个DAO类来了查询导致的。
最终的BookMapper.xml长这样:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.icexmoon.demo.books.book.mapper.BookMapper">
<select id="getPagedBooks" resultMap="BookResultMap">
SELECT b.*, u.`name` AS uname, u.`id` AS uid, u.`open_id` AS uopen_id, u.`password` AS upassword,u.`del_flag` AS udel_flag
FROM book AS b
LEFT JOIN `user` AS u
ON b.`user_id` = u.`id`
WHERE b.`del_flag` = 0
AND u.`del_flag` = 0
</select>
<resultMap id="BookResultMap" type="Book">
<id column="id" property="id"/>
<result column="name" property="name"/>
<result column="description" property="description"/>
<result column="user_id" property="userId"/>
<result column="type" property="type"/>
<result column="extra" property="extra"
typeHandler="BookExtraTypeHandler"/>
<result column="del_flag" property="delFlag"/>
<association property="user" javaType="User">
<id column="uid" property="id"/>
<result column="uopen_id" property="openId"/>
<result column="upassword" property="password"/>
<result column="uname" property="name"/>
<result column="udel_flag" property="delFlag"/>
</association>
</resultMap>
</mapper>
XML改好后我们还需要修改DAO类,将Book中的uname属性修改为user属性以保存关联对象:
(callSuper = false)
(value = "book", autoResultMap = true)
(chain = true)
public class Book implements Serializable {
...
(exist = false)
private User user;
}
现在再执行分页查询,就能看到接口返回类似下面这样的结构:
{
"books": [
{
"id": 15,
"name": "自由与和平",
"description": "自由与和平",
"userId": 1,
"type": 5,
"extra": null,
"delFlag": 0,
"user": {
"id": 1,
"name": "icexmoon",
"password": "123",
"openId": "",
"roles": [],
"delFlag": 0
}
}
],
"pageResponse": {
"total": 9,
"current": 5,
"paging": 3,
"totalRecords": 25
}
}
当然,这个只是简单示例,实际上不需要接口暴露全部的数据给前端,只需要按需从关联对象中提取需要的数据来组织VO对象并返回即可。
以上就是本篇文章的全部内容了,同样的,最终完整示例代码在仓库,有需要可以自取。
谢谢阅读。


文章评论