我们在初学编程语言的时候,除了在诸如变量、控制流程、面向对象这些编程基础内容上会话费大量精力以外,编程语言的内建集合(Collection)或者说内建容器,也同样是重中之重。无论是常用的数组、链表、映射或者是不常用的队列、堆栈等,都需要我们话费大量时间去学习,因为你工作后会发现编写程序的工作中有很大一部分时间是在与这些集合组件打交道。
而我们今天要讨论的迭代器模式,就是为了对于不同内部实现的集合提供一种统一的迭代方式,从而对于客户端来说屏蔽不需要了解的内部实现,可以简单地进行迭代、遍历工作,这是非常棒的一个想法。
注意:因为Python和Java在迭代器实现上有较大不同,所以这里使用Java进行举例说明,在文末会集中说明Python方式的实现应该是怎样的。
外卖服务
假如我们想创建一个外卖服务,为附近的几家餐馆提供统一的线上外卖服务,联系了几家餐馆后,它们给我们提供了用于接入的SDK,简单整合这些SDK后整个系统大概长这样:

虽然表示菜品的菜单项MenuItem已经统一为一个类型,但烧烤店的菜单BarbecueHouseMenu采用数组进行存储,而汉堡店的菜单BurgerJointMenu采用数组列表ArrayList进行存储。很自然,对于这两种不同的集合我们需要使用不同的方式进行遍历输出。
代码相对简单,这里只展示最后的外卖服务TakeOutService类与测试输出,完整代码见:
package pattern9.take_out_v1.src;
import java.util.ArrayList;
/**
* @author 70748
* @version 1.0
* @created 05-7��-2021 14:44:27
*/
public class TakeOutService {
private BarbecueHouseMenu barbecueHouseMenu;
private BurgerJointMenu burgerJointMenu;
public TakeOutService() {
this.barbecueHouseMenu = new BarbecueHouseMenu();
this.burgerJointMenu = new BurgerJointMenu();
}
public void finalize() throws Throwable {
}
public void printMenu() {
System.out.println("This is a Barbecue House menu:");
MenuItem[] menuItems = this.barbecueHouseMenu.getMenuItems();
for (int i = 0; i < menuItems.length; i++) {
if (menuItems[i] != null) {
System.out.println(menuItems[i]);
}
}
System.out.println("This is a Burger Joint menu:");
ArrayList<MenuItem> items = this.burgerJointMenu.getMenuItems();
for (int i=0;i<items.size();i++){
MenuItem menuItem = items.get(i);
System.out.println(menuItem);
}
}
public static void main(String[] args) {
TakeOutService takeOutService = new TakeOutService();
takeOutService.printMenu();
}
}// end TakeOutService
// This is a Barbecue House menu:
// 菜品名称:烤羊肉串 价格:3.0 是否素菜:否
// 菜品名称:烤羊排 价格:10.0 是否素菜:否
// 菜品名称:烤韭菜 价格:2.0 是否素菜:是
// 菜品名称:烤茄子 价格:5.0 是否素菜:是
// 菜品名称:烤土豆 价格:1.0 是否素菜:是
// This is a Burger Joint menu:
// 菜品名称:田园鸡腿堡 价格:15.0 是否素菜:否
// 菜品名称:蔬菜沙拉 价格:10.0 是否素菜:是
// 菜品名称:巨无霸 价格:20.0 是否素菜:否
// 菜品名称:薯条 价格:5.0 是否素菜:是
// 菜品名称:可乐 价格:10.0 是否素菜:是
在这里,我们使用了两种不同的方式遍历菜单项,这是因为两个菜单返回的包含菜单项MenuItem的集合是不同的类型,所以需要使用不同的方式进行迭代。
正如本文一开始所说的,这正是迭代器模式的“用武之地”。
迭代器模式
如果你接触过Python,那肯定听说过迭代器,迭代器可以说深入了Python本身,但这里说的是一般性的迭代器模式,所以可能会和Python的迭代器实现有所差别。
我们看标准的迭代器UML:
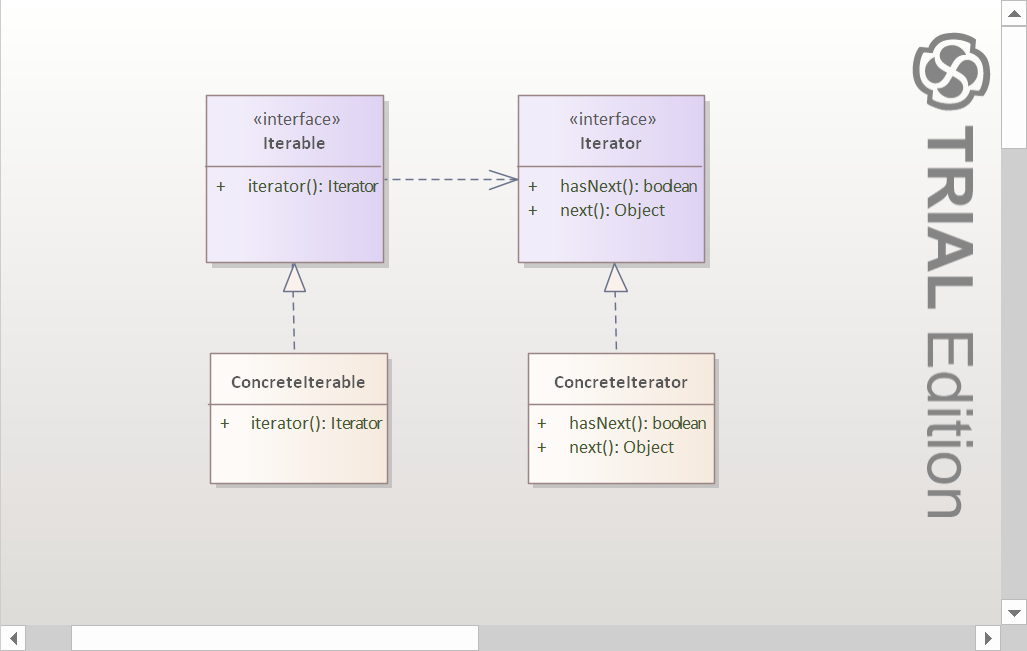
这个设计本身很简单,Iterator是一个标识迭代器的接口,有两个方法:hasNext表示能否从当前的迭代器中获取到下一个元素,next是直接从迭代器中获取到下一个元素。Iterable接口表示一个可迭代的类型,具有一个方法iterator,这个方法会返回一个迭代器,即实现了Iterator接口的类型。而具体的迭代器ConcreteIterator和具体的可迭代类型会分别实现Iterator和Iterable接口。
这里的关键在于,通过实现Iterator和Iterable接口我们可以创建具有统一接口的迭代器和可迭代对象,通过这些多出来的抽象层次,我们可以让外部的客户端程序在不依赖具体集合的实现的情况下单独使用迭代器进行对集合中的元素的遍历。所以通常ConcreteIterator会包含一个集合的句柄用于实现hasNext和next的具体逻辑。
下面我们通过对外卖服务使用迭代器模式重构,来说明迭代器模式具体是如何实现的。
使用迭代器模式
先创建迭代器和可迭代对象接口:
package pattern9.take_out_v2.src;
public interface Iterator {
public boolean hasNext();
public Object next();
}
package pattern9.take_out_v2.src;
public interface Iterable {
public Iterator iterator();
}
分别针对两种不同的集合创建对应的具体迭代器:
package pattern9.take_out_v2.src;
public class ArrayIterator implements Iterator {
private Object[] array;
private int currentIndex = -1;
public ArrayIterator(Object[] array) {
this.array = array;
}
public boolean hasNext() {
if (currentIndex >= array.length - 1 || array[currentIndex+1] == null) {
return false;
}
return true;
}
public Object next() {
Object next = array[currentIndex + 1];
currentIndex++;
return next;
}
}
package pattern9.take_out_v2.src;
import java.util.ArrayList;
public class ArrayListIterator implements Iterator {
private ArrayList<Object> arrayList;
private int nextIndex = 0;
public ArrayListIterator(ArrayList arrayList) {
this.arrayList = arrayList;
}
public boolean hasNext() {
if (nextIndex >= arrayList.size()) {
return false;
}
return true;
}
public Object next() {
return arrayList.get(nextIndex++);
}
}
菜单类BarbecueHouseMenu和BurgerJointMenu实现Iterable接口,改动的代码几乎一致,这里仅展示其中之一:
package pattern9.take_out_v2.src;
import java.util.ArrayList;
/**
* @author 70748
* @version 1.0
* @created 05-7��-2021 14:44:27
*/
public class BurgerJointMenu implements Iterable {
private ArrayList<MenuItem> menuItems = new ArrayList<MenuItem>();
public BurgerJointMenu() {
this.addMenuItem(new MenuItem("田园鸡腿堡", 15, false));
this.addMenuItem(new MenuItem("蔬菜沙拉", 10, true));
this.addMenuItem(new MenuItem("巨无霸", 20, false));
this.addMenuItem(new MenuItem("薯条", 5, true));
this.addMenuItem(new MenuItem("可乐", 10, true));
}
public void finalize() throws Throwable {
}
private void addMenuItem(MenuItem menuItem) {
this.menuItems.add(menuItem);
}
public Iterator iterator() {
return new ArrayListIterator(this.menuItems);
}
}// end BurgerJointMenu
修改测试代码:
package pattern9.take_out_v2.src;
/**
* @author 70748
* @version 1.0
* @created 05-7��-2021 14:44:27
*/
public class TakeOutService {
private BarbecueHouseMenu barbecueHouseMenu;
private BurgerJointMenu burgerJointMenu;
public TakeOutService() {
this.barbecueHouseMenu = new BarbecueHouseMenu();
this.burgerJointMenu = new BurgerJointMenu();
}
public void finalize() throws Throwable {
}
public void printMenu() {
System.out.println("This is a Barbecue House menu:");
this.printMenu(this.barbecueHouseMenu);
System.out.println("This is a Burger Joint menu:");
this.printMenu(this.burgerJointMenu);
}
private void printMenu(Iterable iterable) {
Iterator iterator = iterable.iterator();
while (iterator.hasNext()) {
MenuItem menuItem = (MenuItem) iterator.next();
System.out.println(menuItem);
}
}
public static void main(String[] args) {
TakeOutService takeOutService = new TakeOutService();
takeOutService.printMenu();
}
}// end TakeOutService
// This is a Barbecue House menu:
// 菜品名称:烤羊肉串 价格:3.0 是否素菜:否
// 菜品名称:烤羊排 价格:10.0 是否素菜:否
// 菜品名称:烤韭菜 价格:2.0 是否素菜:是
// 菜品名称:烤茄子 价格:5.0 是否素菜:是
// 菜品名称:烤土豆 价格:1.0 是否素菜:是
// This is a Burger Joint menu:
// 菜品名称:田园鸡腿堡 价格:15.0 是否素菜:否
// 菜品名称:蔬菜沙拉 价格:10.0 是否素菜:是
// 菜品名称:巨无霸 价格:20.0 是否素菜:否
// 菜品名称:薯条 价格:5.0 是否素菜:是
// 菜品名称:可乐 价格:10.0 是否素菜:是
这里的要点在于,我们只关心是否可以获取到两个菜单相关的迭代器,并不关心这两个迭代器如何实现。所以在实现中其实迭代器也可以通过持有两种菜单的引用,而非直接持有数组或者数组列表的引用,同样可以达到目的,但从通用性的角度讲,显然创建数组和数组列表的迭代器比创建两个菜单的迭代器更具有通用性,如果你的其它地方需要数组迭代器,直接拿过去用就是了。
上面我们展示了如何从头到尾在外卖服务中使用一套自己创建的迭代器模式,但其实Java本身是内建了迭代器的相关接口和组件的,我们并不需要从头到尾自己创建,只需要直接使用即可。
Java内建的迭代器接口
Java的内建可迭代接口是java.lang.Iterable,迭代器接口为java.util.Iterator。只要用这两个内建接口替换我们自己创建的相应接口即可。
比如这样:
package pattern9.take_out_v3.src;
import java.util.Iterator;
public class ArrayIterator<T> implements Iterator<T> {
private T[] array;
private int currentIndex = -1;
这里使用泛型改写
ArrayIterator,以避免可能的warning。关于Java的泛型,可以阅读。
至于ArrayListIterator,可以完全删除,因为Java所有的内置集合都已经实现了Iterable接口,我们直接调用iterator获取迭代器即可。
比如这样:
@Override
public Iterator<MenuItem> iterator() {
return this.menuItems.iterator();
}
剩余改动的代码这里不一一展示,可以在获取完整代码。
单一责任原则
迭代器模式体现了一个设计模式原则:单一责任原则。
这个原则指的是,对于我们创建的一个具体的类,应当让其承担相对单一的责任或任务。
比如集合相关的类,其核心任务就是管理内部的元素,比如添加、删除元素。而迭代任务并非其核心任务,好的做法是从其中分离出来,让迭代器去“代劳”,而集合本身只需要关心元素管理即可。
这就是单一责任原则。看起来似乎很容易,但是如果你接触编程久了就会知道,对类的抽象层次,或者说类定义的粒度的把握相当困难,我们都清楚越是将抽象层次细分,越是将类的粒度缩小,越可以提高设计的灵活性,但与此同时,会产生庞大的类数目,会让管理和维护以及工作量随之上升,所以这之间要有所取舍,仔细衡量以制定一个合适的程度。
当然,这种把握属于经验的一部分,并没有捷径或者准则可以提供,唯一获取的方式是持之以恒。
组合模式
我们现在的外卖服务已经运行的很完美了,如果没有新需求的话。
假设我们有一个新的需求:汉堡店想提供一个“活动菜单”,比如和某某知名游戏联名,当然我们并不需要用户说出某种羞耻的台词才能获取到这个菜单😄。
现在我们面临一个问题,需要给汉堡店的菜单添加一个子菜单作为“活动菜单”,但显然目前的设计是无法满足的,因为Java中的集合内的元素都必须是相同的类型,无法将一个菜单塞入菜单项作为元素的集合中(除非使用Object类型的集合,但那样做会带来一些其他的问题)。
所以这里我们必须对现有的菜单存储数据结构进行重构,以满足这种需求。
像这种可以在数据结构中任意节点下添加新节点,并将任意节点视作一个完整数据结构的数据结构,就是树形结构,在设计模式中称之为组合模式。
树形结构
我们看实例:
package pattern9.take_out_v4.src;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
public class Node implements Iterable<Node> {
private LinkedList<Node> children = new LinkedList<>();
private Node parent = null;
public boolean removeFromParent() {
if (parent != null) {
return parent.removeChild(this);
}
return false;
}
public boolean removeChild(Node child) {
if (children.remove(child)) {
child.parent = null;
return true;
}
return false;
}
public void addChild(Node child) {
children.add(child);
child.parent = this;
}
public boolean isLeaf() {
if (children.size() == 0) {
return true;
}
return false;
}
public List<Node> getChildren(){
return this.children;
}
@Override
public Iterator<Node> iterator() {
return new NodeIterator(this);
}
}
树形结构的要点在于节点本身会包含节点类型作为自己的子节点,如果是二叉树一般只会包含两个子节点,可以起名为leftNode和rightNode,如果是普通的树一般会包含一个集合用于保存子节点,我们这里使用LinkedList,因为链表的添加和删除效率要优于ArrayList。
如果对数据结构感兴趣,可以阅读相关的数据结构专业书籍。
我这里实现了一些节点的基本功能,比如添加、删除子节点,为了方便提供一个从父节点删除当前节点的功能,这里保留了一个对父节点的引用this.parent。
同样的,我们可以像对集合那样为树形结构创建一个迭代器:
package pattern9.take_out_v4.src;
import java.util.Iterator;
import java.util.List;
import java.util.Stack;
public class NodeIterator implements Iterator<Node> {
// private Node root;
private Stack<Node> stack = new Stack<Node>();
public NodeIterator(Node node) {
// this.root = node;
this.stack.push(node);
}
@Override
public boolean hasNext() {
if (this.stack.isEmpty()) {
return false;
}
return true;
}
@Override
public Node next() {
Node node = this.stack.pop();
if (node != null && (!node.isLeaf())) {
List<Node> children = node.getChildren();
this.reverseInStack(children);
}
return node;
}
/**
* 将给定的多个Node对象序列倒序压入堆栈
*
* @param nodes
*/
private void reverseInStack(List<Node> nodes) {
Stack<Node> tempStack = new Stack<Node>();
for (Node node : nodes) {
tempStack.push(node);
}
while (!tempStack.isEmpty()) {
Node node = tempStack.pop();
this.stack.push(node);
}
}
}
这个迭代器的关键在于使用一个堆栈用于记录迭代时的中间数据。
一开始我的实现思路是使用递归遍历树形结构,并将遍历过程中的所有节点保存在一个
LinkedList中,最后直接返回LinkedList的迭代器即可。但这样做的空间复杂度和事件复杂度显然都要高于使用堆栈的方案。这里的实现与《Head First 设计模式》略有不同,因为我想实现一个通用的树形结构和与之配套的迭代器,而非在菜单类中实现迭代器。
现在我们的树形结构,或者说组合模式已经创建完毕,如果想在代码中使用这种结构很简单,只要继承Node即可。
使用组合模式
现在我们已经有了树形结构和与之配套的迭代器,现在只要让相关的菜单类继承Node即可以作为树形结构的节点来使用,然后组合成我们需要的任意菜单结构。
为了方便,这里创建一个基类Menu作为特异化菜单类型的基类:
package pattern9.take_out_v4.src;
public class Menu extends Node {
private String name;
public Menu(String name) {
this.name = name;
}
public void addMenuItem(MenuItem menuItem) {
this.addChild(menuItem);
}
@Override
public String toString() {
return "This is a " + this.name + " menu:";
}
}
对于BurgerJointMenu和BarbecueHouseMenu现在只需要简单地继承Menu即可,可以删除大量不需要的方法:
package pattern9.take_out_v4.src;
/**
* @author 70748
* @version 1.0
* @created 05-7��-2021 14:44:27
*/
public class BurgerJointMenu extends Menu {
public BurgerJointMenu() {
super("burger joint");
this.addMenuItem(new MenuItem("田园鸡腿堡", 15, false));
this.addMenuItem(new MenuItem("蔬菜沙拉", 10, true));
this.addMenuItem(new MenuItem("巨无霸", 20, false));
this.addMenuItem(new MenuItem("薯条", 5, true));
this.addMenuItem(new MenuItem("可乐", 10, true));
}
public static Menu getSpecialMenu() {
Menu menu = new Menu("Burger Joint's special");
menu.addMenuItem(new MenuItem("元神全家桶", 50, false));
menu.addMenuItem(new MenuItem("崩三全家桶", 60, false));
menu.addMenuItem(new MenuItem("吃鸡全家桶", 70, true));
return menu;
}
}// end BurgerJointMenu
实质上这两个类也可以省略,我们完全可以通过简单工厂来创建相应的菜单实例,但为了延续之前的测试代码,这里就不那样做了,只不过新的特殊菜单使用一个简单工厂方法getSpecialMenu来创建。
此外,菜单项也必须继承自Node,这样才能通过树形结构加载到Menu节点下边:
public class MenuItem extends Node{
private String name = "";
private double price = 0;
private boolean vegetarian = false;
public MenuItem(String name, double price, boolean vegetarian) {
this.name = name;
this.price = price;
this.vegetarian = vegetarian;
}
@Override
public void addChild(Node child) {
throw new UnsupportedOperationException();
}
需要注意的是在MenuItem中我们重写了addChild方法,并抛出一个UnsupportedOperationException类型的异常,这是很自然的,因为菜单项必然是叶子节点,显然不允许再被添加子节点。
测试代码:
package pattern9.take_out_v4.src;
import java.util.Iterator;
/**
* @author 70748
* @version 1.0
* @created 05-7��-2021 14:44:27
*/
public class TakeOutService {
private BarbecueHouseMenu barbecueHouseMenu;
private BurgerJointMenu burgerJointMenu;
private Menu allMenu;
public TakeOutService() {
this.allMenu = new Menu("all menu:");
this.barbecueHouseMenu = new BarbecueHouseMenu();
this.burgerJointMenu = new BurgerJointMenu();
this.burgerJointMenu.addChild(BurgerJointMenu.getSpecialMenu());
this.allMenu.addChild(barbecueHouseMenu);
this.allMenu.addChild(burgerJointMenu);
}
public void printMenu() {
this.printMenu(this.allMenu);
}
private void printMenu(Iterable<Node> iterable) {
Iterator<Node> iterator = iterable.iterator();
while (iterator.hasNext()) {
Node menuItem = iterator.next();
System.out.println(menuItem);
}
}
public static void main(String[] args) {
TakeOutService takeOutService = new TakeOutService();
takeOutService.printMenu();
}
}// end TakeOutService
// This is a all menu: menu:
// This is a barbecue house menu:
// 菜品名称:烤羊肉串 价格:3.0 是否素菜:否
// 菜品名称:烤羊排 价格:10.0 是否素菜:否
// 菜品名称:烤韭菜 价格:2.0 是否素菜:是
// 菜品名称:烤茄子 价格:5.0 是否素菜:是
// 菜品名称:烤土豆 价格:1.0 是否素菜:是
// This is a burger joint menu:
// 菜品名称:田园鸡腿堡 价格:15.0 是否素菜:否
// 菜品名称:蔬菜沙拉 价格:10.0 是否素菜:是
// 菜品名称:巨无霸 价格:20.0 是否素菜:否
// 菜品名称:薯条 价格:5.0 是否素菜:是
// 菜品名称:可乐 价格:10.0 是否素菜:是
// This is a Burger Joint's special menu:
// 菜品名称:元神全家桶 价格:50.0 是否素菜:否
// 菜品名称:崩三全家桶 价格:60.0 是否素菜:否
// 菜品名称:吃鸡全家桶 价格:70.0 是否素菜:是
我们现在在外卖服务中创建了一个树型节点allMenu作为总菜单,之前的各种菜单可以直接挂载在这个总菜单下面。这里仅在Menu中封装了addMenuItem,其实还可以封装一个addSubMenu作为添加菜单的方法,这样就不需要直接调用addChild了,这个工作留给读者吧。完整代码见。
现在我们的菜单结构相当灵活,甚至可以单独打印某个子菜单或者菜单项,都是可以的。这得益于我们给树形结构配套的迭代器。
空迭代器
因为实现方式的不同,我们这里并没有涉及到空迭代器(因为对于给定的节点,返回的迭代器中至少会包含节点本身),但如果返回的迭代器会是空的,此时直接使用一个空迭代器作为返回值是个不错的选择,这往往比直接返回null要好的多。
实现起来也非常简单:
package pattern9.take_out_v4.src;
import java.util.Iterator;
public class NullIterator<T> implements Iterator<T> {
@Override
public boolean hasNext() {
return false;
}
@Override
public T next() {
return null;
}
}
筛选出素食
我们现在已经有完善的菜单迭代方案了,所以这并非什么难事:
private void printVegetMenuItem(Menu menu){
System.out.println("vegetarian menu is:");
for (Node node : menu) {
if (node instanceof MenuItem){
MenuItem menuItem = (MenuItem)node;
if(menuItem.isVegetarian()){
System.out.println(menuItem);
}
}
}
}
因为我们需要判断是否为素菜,所以这里不得不使用instanceof关键字进行类型判断,《Head First 设计模式》中是让MenuItem和Menu具有了相同的基类,然后在基类中进行约束,并对于不支持该方法的Menu中返回异常来进行区分,这样只需要捕获并忽略异常即可,这是两种不同的思路,这里不做展示,有兴趣的可以阅读该书的相应章节。完整代码见。
Python版本
Python语言本身深度融入了迭代器,并且还进一步衍生出生成器,所以除了上边Java中使用堆栈实现迭代器以外我们有一个额外的选择:使用生成器实现。
下面展示Python版本的Node代码:
from collections.abc import Iterator
class Node():
def __init__(self) -> None:
self.children: list = list()
self.parent: Node = None
def removeFromParent(self) -> bool:
if self.parent is not None:
return self.parent.removeChild(self)
return False
def removeChild(self, child: "Node") -> bool:
self.children.remove(child)
child.parent = None
return True
def addChild(self, child: "Node"):
self.children.append(child)
child.parent = self
def isLeaf(self):
if len(self.children) == 0:
return True
return False
def getChildren(self) -> list:
return self.children
def __iter__(self) -> Iterator:
yield self
if self.isLeaf():
return
#对子节点进行遍历
childNode: "Node"
for childNode in self.getChildren():
yield from childNode.__iter__()
在Python中我们只要实现__iter__方法即可以将类型变成可迭代类型(Iterable)。
__iter__方法要求我们返回一个迭代器(Iterator),当然我们可以像Java那样单独创建一个NodeIterator,但是那样做需要使用额外的数据结构,比如上边展示的那样使用“堆栈”,消耗了空间复杂度。Python中我们可以用一种额外的思路,即直接将__iter__方法变成一个生成器方法,即直接在其中使用yield关键字产生值,而不是使用return。这样做会在解释器通过iterator()调用Node的__iter__时候直接获取到一个生成器,进而通过这个生成器来进行遍历。
具体的生成器代码对比之前的示例来说相当精简,但有点难以理解,我这里简单解释一下:
-
不管是中间节点还是叶子节点,都先返回自己,即
yield self。 -
如果是叶子节点,结束遍历,即使用
return,或者raise StopIteration()也是可以的。 -
如果是中间节点,遍历所有子节点,在遍历的过程中,不论子节点是中间节点还是叶子节点,我们都可以将子节点的遍历过程“委托”给该节点的生成器,即使用
yield from childNode.__iter__()即可。注意:调用生成器函数返回的是一个生成器,而非其产出的值。
如果你还不熟悉Python的迭代器,可以阅读。
可以看到,通过使用生成器函数,我们实现了堆栈才能实现的复杂逻辑,并且降低了空间复杂度。
但可以预见的是在解释器调用生成器的时候,运行中间挂起的操作会有额外开销,但这些不在我们算法时间空间复杂度的讨论范围内,而且这种语言的内部机制一般会进行相当程度的优化,我们无需担心。
Python版本的外卖服务的其它部分代码几乎别无二致,这里不做赘述,完整代码见。
关于迭代器模式的介绍就到这里了,谢谢阅读。


文章评论